Leetcode Hot 100 | 链表
|字数总计:3.4k|阅读时长:14分钟|阅读量:
思想
看看链表吧。链表算是数据结构中很基础的一类题目,我也刷过很多遍,这应该是第三遍,没什么好说的。如果穿越回去,再让我做数据结构的期末题,我想,应该不会很有难度。我依稀记得,当时的期末是个合并有序链表的题,嗐,不过是 Leetcode Easy 而已。
题目
2. Add Two Numbers
这题给了链表组成的两个数字,靠头部的是低位。让我们给这两个数做加法运算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
int carry = 0;
ListNode dummy(0);
ListNode* curr = &dummy;
while (l1 || l2 || carry) {
int sum = carry;
if (l1) {
sum += l1->val;
l1 = l1->next;
}
if (l2) {
sum += l2->val;
l2 = l2->next;
}
curr->next = new ListNode(sum % 10);
curr = curr->next;
carry = sum / 10;
}
return dummy.next;
}
};
|
比较巧妙的是两个条件判断,如果指针有效,则取值,否则当作是 0,不计入 sum。此外,有个头结点或许会比较方便,此外对于 new 的用法也要熟悉。
19. Remove Nth Node From End of List
这题的要求是,删除链表倒数第 n 个结点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode dummy(0, head);
ListNode* slow = &dummy;
ListNode* fast = &dummy;
for (int i = 0; i <= n; i++) {
fast = fast->next;
}
while (fast) {
slow = slow->next;
fast = fast->next;
}
slow->next = slow->next->next;
return dummy.next;
}
};
|
面试常见题,初见会觉得比较难以理解:难道把所有的结点加入一个有限长度的队列中,最后取所谓的倒数第 n 个?有的人是这样做的,也能 AC,但更正统的做法是双指针。
在链表中,经常会看到双指针的身影,或者说快慢指针,一个走在前面,一个在后面亦步亦趋。这种组合有时候会带来非常惊人的效果。
这题双指针的套路比较容易,先让快指针多走几步,类似于侦察兵。之后快慢指针同步前进。当侦察兵探测到链表结束了,后面的慢指针就知道到达目的地了。思路就是如此,只不过需要注意几个细节:
- 因为要删除倒数第 n 个结点,所以应该让慢指针停在倒数第 n + 1 个结点;
- 如果恰好删除第一个结点,不用头结点会很难维护,所以引入一个
dummy。
21. Merge Two Sorted Lists
合并两个有序链表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode dummy(0);
ListNode* curr = &dummy;
while (list1 && list2) {
if (list1->val < list2->val) {
curr->next = list1;
list1 = list1->next;
} else {
curr->next = list2;
list2 = list2->next;
}
curr = curr->next;
}
curr->next = list1 ? list1 : list2;
return dummy.next;
}
};
|
没什么好说的,当年的期末题。这道题是后续很多题目的基础,比如快速排序。
23. Merge k Sorted Lists
如果要合并 k 个有序列表,该怎么办?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| class Solution {
private:
struct cmp {
bool operator()(ListNode* a, ListNode* b) {
return a->val > b->val;
}
};
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
priority_queue<ListNode*, vector<ListNode*>, cmp> pq;
for (ListNode* li : lists) {
if (li) {
pq.push(li);
}
}
ListNode dummy(0);
ListNode* curr = &dummy;
while (!pq.empty()) {
curr->next = pq.top(); pq.pop();
curr = curr->next;
if (curr->next) {
pq.push(curr->next);
}
}
return dummy.next;
}
};
|
使用一个优先队列来维护。思想是,用一个最小堆,堆顶是最小值的地址,这样每次可以定位到 k 个链表头部最小的结点。仅此而已。
需要讲解的是关于最小堆的维护,它接收 3 个参数:元素类型、底层容器和比较器。前面两个一般不必纠结,举个例子元素类型是 int,那底层容器就用 vector<int>,以此类推。
比较器,C++ 要求必须是一个类型,所以不能直接写函数,必须定义一个对象。此外,对于这个对象,还必须把比较函数定义为函数调用运算符重载的格式,也就是 operator()(...),这指的是这个对象可以像函数一样调用。
你说,能不能做点修改,不改变默认的优先队列比较器?实际上这题不可以,因为传入的是指针,比较的是指针的值。如果是大根堆变成小根堆这种需求,在值上加个负号便能解决。
此外,怎样理解大根堆和小根堆?类似于大端序和小端序,在堆顶(队首)的元素如果最大,就是大端,反之是小端。以及,怎样理解比较器的不等号和大根小根的关系?如果 a ?? b 成立,则 b 优先于 a。所以如果写 a < b,意味着这是个大根堆。
24. Swap Nodes in Pairs
对换结点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode dummy(0, head);
ListNode* curr = &dummy;
while (curr->next && curr->next->next) {
ListNode* a = curr->next;
ListNode* b = a->next;
a->next = b->next;
b->next = a;
curr->next = b;
curr = a;
}
return dummy.next;
}
};
|
指针小游戏。还是有个头结点比较方便,此外,多写点临时指针指向结点会容易写一些。这题是下一题的特殊情形,所谓的对换,不也是反转?
25. Reverse Nodes in k-Group
对于链表,每 k 个长度,分别进行反转。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| class Solution {
private:
void reverseList(ListNode* start, ListNode* end) {
ListNode* prev = end;
ListNode* curr = start->next;
ListNode* next;
while (curr != end) {
next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
start->next = prev;
}
public:
ListNode* reverseKGroup(ListNode* head, int k) {
ListNode dummy(0, head);
ListNode* prevGrp = &dummy;
while (true) {
ListNode* kth = prevGrp;
for (int i = 0; i < k && kth; i++) {
kth = kth->next;
}
if (!kth) return dummy.next;
ListNode* start = prevGrp;
ListNode* end = kth->next;
prevGrp = prevGrp->next;
reverseList(start, end);
}
return nullptr;
}
};
|
这时候提取出一个辅助函数会很有帮助。
reverseList 接收起点和终点(不包含要反转的元素),目标是,反转起点和终点之间的序列,让起点指向反转后序列的头部,反转后序列的尾部指向终点。
有了这个函数后,就只需要确保各个组的起点和终点分别在哪里。同时记得维护下一组的起点位置,完成传递。我想,这样就不会很困难了。
138. Copy List with Random Pointer
复制一个链表,链表除了 next 指针外,还存在 random 指针,指向链表的任何一个合法位置,或者是空指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| class Solution {
public:
Node* copyRandomList(Node* head) {
if (!head) return head;
Node* curr = head;
while (curr) {
Node* copy = new Node(curr->val);
copy->next = curr->next;
curr->next = copy;
curr = copy->next;
}
curr = head;
while (curr) {
if (curr->random) {
curr->next->random = curr->random->next;
}
curr = curr->next->next;
}
curr = head;
Node* copyCurr;
Node dummy(0, curr->next);
while (true) {
copyCurr = curr->next;
curr->next = copyCurr->next;
curr = curr->next;
if (curr) copyCurr->next = curr->next;
else break;
}
return dummy.next;
}
};
|
关键是想到亦步亦趋这种构造方式,每个原始结点后面跟着复制后的结点,这样方便定位 random 指针的位置。
随后,分成 3 步:
- 构造亦步亦趋链表;
- 处理
random 指针;
- 拆分。
关于拆分这一步,现在的算法写的不是特别好,或许有更好的方式,但总之要解决问题。
最后,小地方是记得处理输入为空的情况。
141. Linked List Cycle
链表判环,经典题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode* slow = head;
ListNode* fast = head;
while (fast && fast->next) {
slow = slow->next;
fast = fast->next->next;
if (slow == fast) return true;
}
return false;
}
};
|
快慢指针,快的每次走两步,慢的每次走一步,如果二者相遇了,说明有环。如果退出循环,说明 fast 走到了结尾,没有环。
链表判环和 DAG 判环不太一样,后者是用拓扑排序。要用排课助手那道题的思路。
142. Linked List Cycle II
链表判环,还需要返回进入环的位置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode* slow = head;
ListNode* fast = head;
while (fast && fast->next) {
fast = fast->next->next;
slow = slow->next;
if (slow == fast) {
slow = head;
while (slow != fast) {
slow = slow->next;
fast = fast->next;
}
return slow;
}
}
return nullptr;
}
};
|
上一题的提高版,一个小小的数学问题。
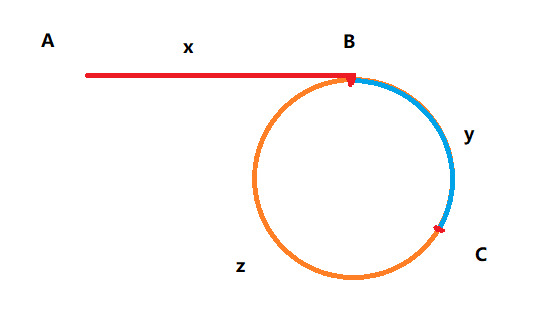
假设快慢指针在 C 点相遇,因为快指针的速度是慢指针的 2 倍,有这个式子成立:
$$
x + y + z + y = 2 (x + y)
$$
化简得到
$$
x = z
$$
所以,一开始还是快指针比慢指针走的快一倍,在二者相遇后,把快慢指针的一个挪到起点,随后二者按照相同的速度前进,那么就会同时到达 B 点,也就是我们想要的起点。
146. LRU Cache
这题算是一个小模拟,让我们实现 LRU 缓存,要求 get 和 put 的时间复杂度都是 $O(1)$。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| class LRUCache {
private:
struct Node {
int key, val;
Node* prev;
Node* next;
Node() {};
Node(int _key, int _val) : key(_key), val(_val) {};
};
Node* head;
Node* tail;
unordered_map<int, Node*> mp;
int capacity;
void remove(Node* node) {
node->prev->next = node->next;
node->next->prev = node->prev;
}
void insertHead(Node* node) {
node->next = this->head->next;
node->prev = head;
node->next->prev = node;
head->next = node;
}
public:
LRUCache(int capacity) {
this->capacity = capacity;
this->head = new Node();
this->tail = new Node();
this->head->next = this->head->prev = this->tail;
this->tail->next = this->tail->prev = this->head;
}
int get(int key) {
if (mp.count(key) == 0) return -1;
Node* pNode = mp[key];
remove(pNode);
insertHead(pNode);
return pNode->val;
}
void put(int key, int value) {
if (mp.count(key)) {
mp[key]->val = value;
remove(mp[key]);
insertHead(mp[key]);
} else {
Node* pNode = new Node(key, value);
insertHead(pNode);
mp[key] = pNode;
if (mp.size() > capacity) {
Node* pRm = tail->prev;
remove(pRm);
mp.erase(pRm->key);
delete pRm;
}
}
}
};
|
代码量还是比较大的,核心在于需要使用双向链表便于维护缓存队列,以及使用一个字典快速查表。
讲几个需要注意的语法特征:
- 何时需要
this->?成员变量和局部变量同名无法区分时,所以这个例子其实只有 capacity 的 this-> 是必要的;
new 和 delete 要配对,不然内存泄漏,注意 delete 的位置,remove 函数不负责回收;- 注意业务逻辑,同时维护链表和字典。
148. Sort List
快速排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| class Solution {
private:
ListNode* mergeList(ListNode* l1, ListNode* l2) {
ListNode dummy(0);
ListNode* curr = &dummy;
while (l1 && l2) {
if (l1->val < l2->val) {
curr->next = l1;
l1 = l1->next;
} else {
curr->next = l2;
l2 = l2->next;
}
curr = curr->next;
}
curr->next = l1 ? l1 : l2;
return dummy.next;
}
ListNode* findMid(ListNode* head) {
ListNode* slow = head;
ListNode* fast = head->next;
while (fast && fast->next) {
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
public:
ListNode* sortList(ListNode* head) {
if (!head || !head->next) {
return head;
}
ListNode* mid = findMid(head);
ListNode* l1 = head;
ListNode* l2 = mid->next;
mid->next = nullptr;
return mergeList(sortList(l1), sortList(l2));
}
};
|
如果分成几个辅助函数,会好一点。一个辅助函数负责合并有序链表,还有一个负责找到中点。
讲解一下找中点的这个函数,对于偶数长度,找到的是中间偏左;奇数长度则是正中间。这样的好处是,可以比较方便的断开后继。
最后,要注意的是,传入 mergeList 的应该是 sortList 的返回值,而不是原始的 l1、l2。返回值返回的才是真正的队首,原始的不一定是队首。
160. Intersection of Two Linked Lists
找出两个链表的交点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode* pA = headA;
ListNode* pB = headB;
while (pA != pB) {
pA = pA ? pA->next : headB;
pB = pB ? pB->next : headA;
}
return pA;
}
};
|
这题唯一要注意的地方是,两个链表可能没有交点。因此条件表达式的条件必须是 pA/B,不能是 pA/B->next,后者会导致在不存在交点时,pA 和 pB 永远不相等,从而导致死循环的出现。
206. Reverse Linked List
反转链表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* curr = head;
while (curr) {
ListNode* next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
return prev;
}
};
|
小手撕,没什么多说的。记得在写代码的时候,脑中有结点指针变化的过程,这样会比较顺。
234. Palindrome Linked List
回文链表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| class Solution {
private:
ListNode* findMid(ListNode* head) {
ListNode* fast = head->next;
ListNode* slow = head;
while (fast && fast->next) {
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* curr = head;
while (curr) {
ListNode* next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
return prev;
}
public:
bool isPalindrome(ListNode* head) {
ListNode* mid = findMid(head);
ListNode* l1 = head;
ListNode* l2 = mid->next;
mid->next = nullptr;
l2 = reverseList(l2);
while (l2) {
if (l1->val != l2->val) return false;
l1 = l1->next;
l2 = l2->next;
}
return true;
}
};
|
思路不难,写的东西比较多。首先需要找到中点,这是一个辅助函数,注意 fast 的位置;之后是反转链表函数,上一题刚刚做过。最后是简单的循环与比较,数值保证了 l1 更长,所以 l1 末尾多出来的字符不考虑。比如 12321 的 3 不必比较。
