
CS50AI - 第 4 章 - 学习
学习是当下 AI 领域非常热门的话题。机器学习已经渗透到科学研究的各个领域。
很简单地,基于图像识别来判断是不是有坏果;或者,在加密了的网络中,基于机器学习来识别流量中的恶意流量。
所以有必要学习一下机器是如何来学习的。
机器学习有一些取巧的成分。感觉,有点像大人教小孩子如何学习知识一样。因为我们不知道如何来编写一套行之有效的算法,所以寄希望于给定一些提示,让机器自己根据提示选择更好的路径,从而完成一项任务。
监督学习(Supervised Learning)
监督学习,顾名思义,是需要人来监督的。
人,做了什么呢?
标注数据集。
监督学习的底层思路就是寻找一个近似函数。这个函数对于给定的输入,输出一个估计的结果。我们的目标就是提供大量的输入,根据输入,调整各个参数,得到近似函数。最后,针对新的输入,检验这个函数能不能输出预期结果。
找这个函数,目的是什么?目的是解决两种问题:
- 分类问题;
- 回归问题。
二者的区别在于,分类问题的值域是离散的,好果子/坏果子;下雨、不下雨;回归问题是连续的,如收入等指标。
分类问题
对于分类问题,解决思路有两种:
- 邻居;
- 感知机(Perceptron)。
- 支持向量机(Support Vector Machines)
第一个思路很好理解,其底层逻辑是:近朱者赤,近墨者黑。评判你是什么样的,那就看看你周围的人是什么样的。特别的,邻居思路氛围两种,一个是考察最近的邻居;另一种考虑的更多,考虑 $k$ 个最近的邻居,这样可以避免目光狭隘。
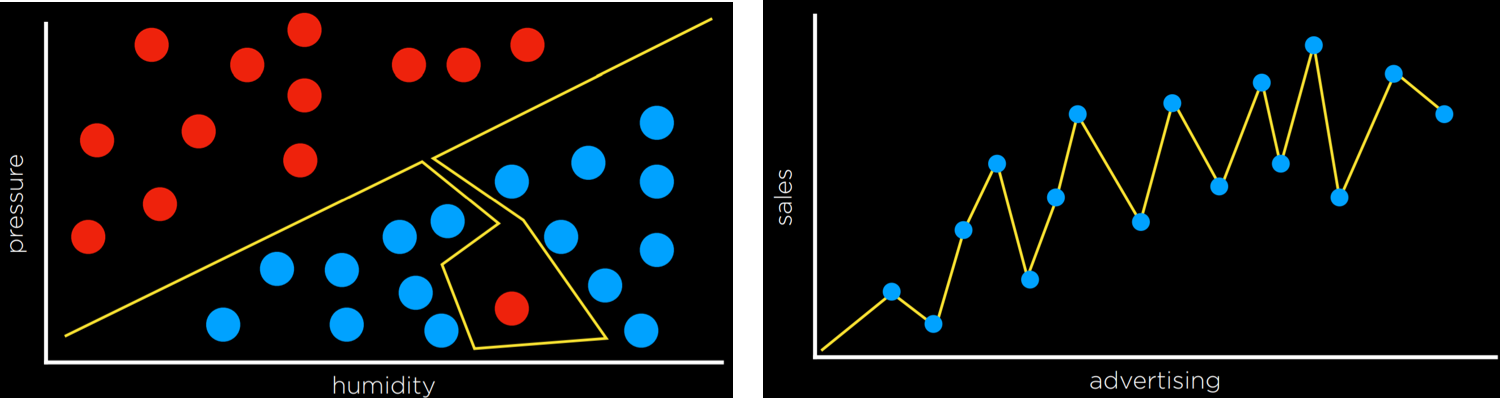
第二个思路是进行划分。第一个思路的不足是,不管是一个邻居还是多个邻居,本质上都是邻居,都是局部的图景。而第二个思路是寻找一条线对不同情况进行划分,就好像一个函数,针对不同的输入,$> 0$,是一种情况;$< 0$ 是另外一种情况。
第三种则是使用支持向量来辅助进行问题的划分。目标是找到与多种情况相距最远的那条分割线,比如下图。

支持向量机的一个好处是,可以进行超过二维的边界寻找,以及寻找非线性的边界。
对于我们得到的结果,又有两种可能。一个是非黑即白的硬门槛,另一种是软门槛。这里的硬和软指的是多种情况的边界的陡峭程度。
比如,硬门槛,在一个边界值左侧,就是情况 $A$,否则是情况 $B$。但这种分类标识不了确定度,即我们有多确定输入属于某种情况。
显然,离边界远的输入,我们更加肯定其属于某种情形;否则不太肯定。这就是软门槛的作用了,它的边界曲线较为平滑,使得我们可以表示输入属于某种情况的概率。
回归问题
前面的分类问题,我们要寻找一个边界,把多个结果分开来。这里,我们要做的是,找到一条曲线,让结果靠近这条曲线。
直观上,有点像数学里的描点作图。
结果评价
如何评价我们训练出来的模型,或者是得到的函数?
一种方法是使用 Loss Function,用来衡量我们匹配错误的数量。比如,本来是好果子,被分类成了坏果子,计数器 +1;反之亦然。
上面的这种评价标准叫 0-1 Loss Function。
除此之外,还有
- $L_{1}: L(actual, predicted) = |actual - predicted|$
- $L_{2}: L(actual, predicted) = (actual - predicted)^{2}$
有点数理统计的味道了。二者的差别在于对偏离量的权重不一样。
$L_1$ 认为偏离远近,权重相同,函数值随偏移量是线性增长的;$L_2$ 认为,偏离更远,权重更大,呈指数增长。
过拟合(Overfitting)
过拟合是常常为人乐道,并且很常见的一个问题。它的问题就是,只关注局部,而忘记了整体。不过也不能怪罪机器,因为,我们给予它的就是那部分数据集呢。
就好像高考一样,多少人为了高考这一个目标,反复训练。确实,在高考这一个目标上取得了卓著的成绩,但是未来呢?当面对更更广阔的人生时,难道还要按照既定路线前进吗?
过拟合就是钻牛角尖,虽然对个别问题(我们提供的数据集)有着极高的正确率,超然的效果,然而换一个数据集就抓瞎。看看这两张图吧:
正则化(Regularization)
为了避免过拟合,我们就想让机器给出的求解函数一般化。做法是,给定一个函数:
$$
cost(h) = loss(h) + \lambda complexity(h)
$$
毕竟,我们之前的指标只在乎损失,那么机器当然就线性思维地追求降低损失啦。不过就像哪位数学家说过的一样,问题的解决公式应该是优雅的,所以,我们可以把公式复杂度也纳入考虑,太高,则认为开销也很大。
而具体来说,我们要检验得到的模型是否过拟合了,可以采用 Holdout Cross Validation,把数据集分成两部分:训练集和测试集。
上面的方法有个不足,那就是有些数据只用来检验,没用来测试,所以有个更好的方法叫 k-Fold Cross-Validation。让每个集合都当一次测试集,其余作为训练集,来检验一下我们的模型是否有普适性。
scikit-learn
这是一个 Python 的 library,可以实现上文提到的许多模型。
强化学习
强化学习基于行为主义,让我们的小机器人暴露在一个环境(的某一个状态)中。每当它采取一个行动,环境给予它一个新的状态,以及反馈(奖励 or 惩罚)。
我们的小机器人随着逐渐学习,就会选择获得更多奖励的路线。
听起来像个状态机。确实是这样。就像之前文章提到的马尔科夫链,只不过这里是一个马尔科夫决策过程,让小机器人有机地参与到状态转移的过程中。
Q-Learning
一个实现强化学习的模型是 Q-Learning,$Q(s, a)$ 针对 state 和 action 返回一个估计的奖励值。
核心公式是:
$$
Q(s, a) \leftarrow Q(s, a) + \alpha ((r + \gamma \max_{a^{\prime}}{Q(s^{\prime}, a^{\prime})}) - Q(s, a))
$$
其中,$\alpha$ 表示一个学习系数,它决定了数据改变的速度,$\alpha = 1$,则不考虑旧的经验;另一个极端是不考虑新的经验。
另一个系数 $\gamma$ 则决定了对于未来可能获得的值的重视程度,即对 $Q(s^{\prime}, a^{\prime})$ 的重视程度。$r$ 表示这一步可以获得的奖励,而 $Q(s^{\prime}, a^{\prime})$ 表示未来可能获得的奖励。
这里,我们来到了一个 Explore vs. Exploit 的权衡问题。到底让 AI 循着已经成功的老路走,求稳;还是让它多多探索,找到潜在更优解呢?
贪心算法永远是走相同的老路,就像单曲循环,很可能错过了一些同样对胃口的歌曲。
这里采用了一个 $\varepsilon$ 贪心算法,其中 $\varepsilon$ 决定了想要随机移动的几率。也就是说,$1 - \varepsilon$ 的情况下,算法会选择最优解;剩下的 $\varepsilon$ 概率,会选择一个随机的移动。
所以其实算法是相通的,这和我们上一节课学到的爬山算法,或者是模拟退火算法都有相通之处。
另一种强化学习算法是只在游戏结束后才给予反馈,而不是每一步都有反馈。
同样的,对于那些状态更多的游戏,如国际象棋,可能需要用一些函数来估计,就像 $\alpha, \beta$ 剪枝一样。
无监督学习(Unsupervised Learning)
无监督学习的好处是,不需要标注数据集啦。但是又怎样做到无监督呢?
这里接触到的一个概念叫:Clustering(簇、丛),有点像一串葡萄那种感觉。
Clustering 的目标是,针对给定的输入,把他们分类为相似的组。比如,基因的分类、网络流量的分类、图像的分类等等。
k-means Clustering 的算法是用来进行一个 clustering 任务。
1 | |
