
爬虫+Web | 同济大学 1 系统通知公告备份与提醒
缘起
- 同济大学 1 系统 是同济大学的教学信息管理平台,发布教务教学的通知公告。发布的通知较为重要,但是过了一段时间便会下架,不给人回看的可能。
- 在计科导的网站大作业编写的网站没有用户的登录注册等功能,如果因为作业时间仓促而明文存储密码,没什么意义。因此在寒假编写一个生产上较为安全的用户系统。
文章将按模块来展开,梳理网站实现的大部分细节。文章比较长,读者可以选感兴趣的部分阅读。
网站在:同济大学通知公告备份站。
Github 仓库在:Github
爬虫——数据获取
统一身份认证
获取数据需要通过的第一道关卡是统一身份认证,因为如果不登录,是获取不了任何内容的,会返回 401 错误。上图是老的身份认证系统,现在不需要手动点击验证码、只需要点击登录按钮,相对还容易些,不然,如何通过验证码也是个问题。
在用户输入了用户名和密码后,发生了什么事情呢?
初步认识
在 Network 面板中,注意到 1 系统会向 https://iam.tongji.edu.cn/idp/authcenter/ActionAuthChain?... 发送 URL编码后的 如下内容:
1 | |
当然,我这里说 注意到,其实有点马后炮之嫌,因为如果不打断点的话,页面直接会跳转到 1 系统,而在进入到 1 系统后再在
Network中查看,是看不到这一请求历史的!(因为这是个js请求) 换句话说,在后面使用requests模拟请求时,如果缺失了这一步,登录不成功,获取不到Cookie!我在这一步卡了很久。不过现在发现,如果在Network面板勾选Preserve log就能看到按下登录按钮后发生的所有事情,而不会因为页面跳转失去之前的内容。这样也就能解决这一问题了。
这些内容是如何获得的?
调试
打个断点调试吧!找到登录按钮的元素,看看 @click,也就是鼠标单击后会发生什么。
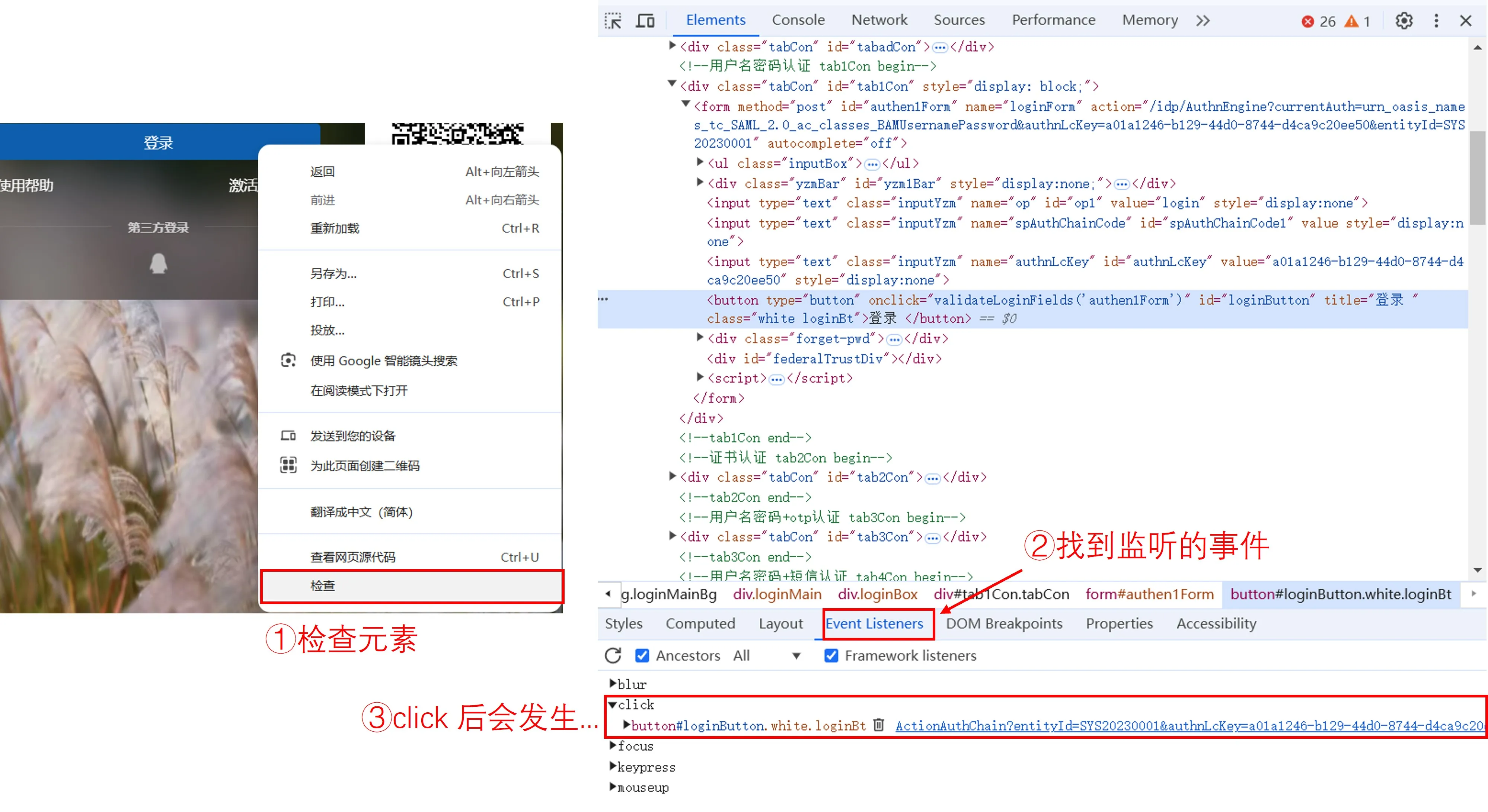
点击③红框中的链接,到了下面的页面:
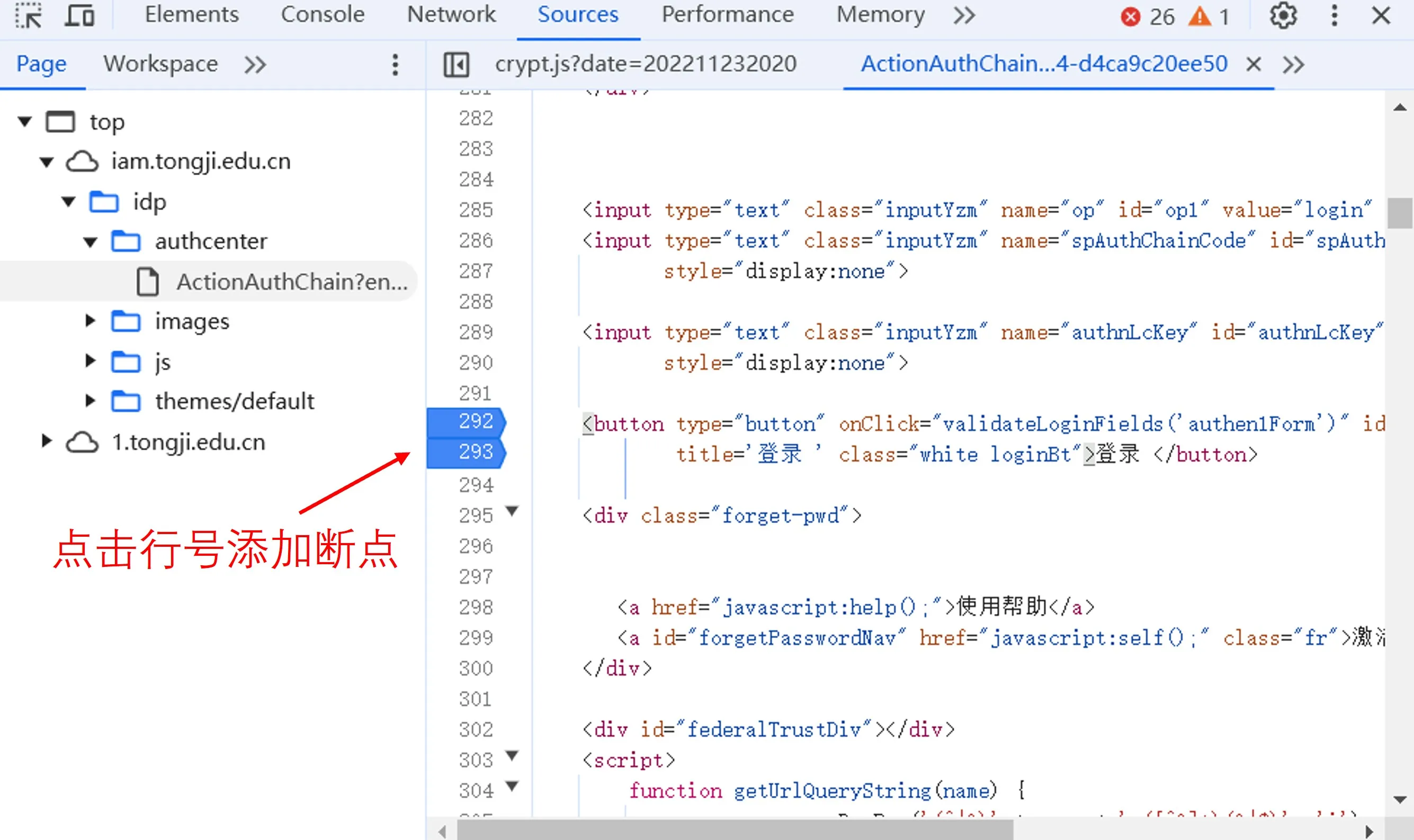
点击左侧的行号,就会添加断点。这样,等我们按下登录按钮后,页面就不会一下子跳转到登录后的状态,而是一步步执行,让我们可以知道,到底登录过程发生了什么。
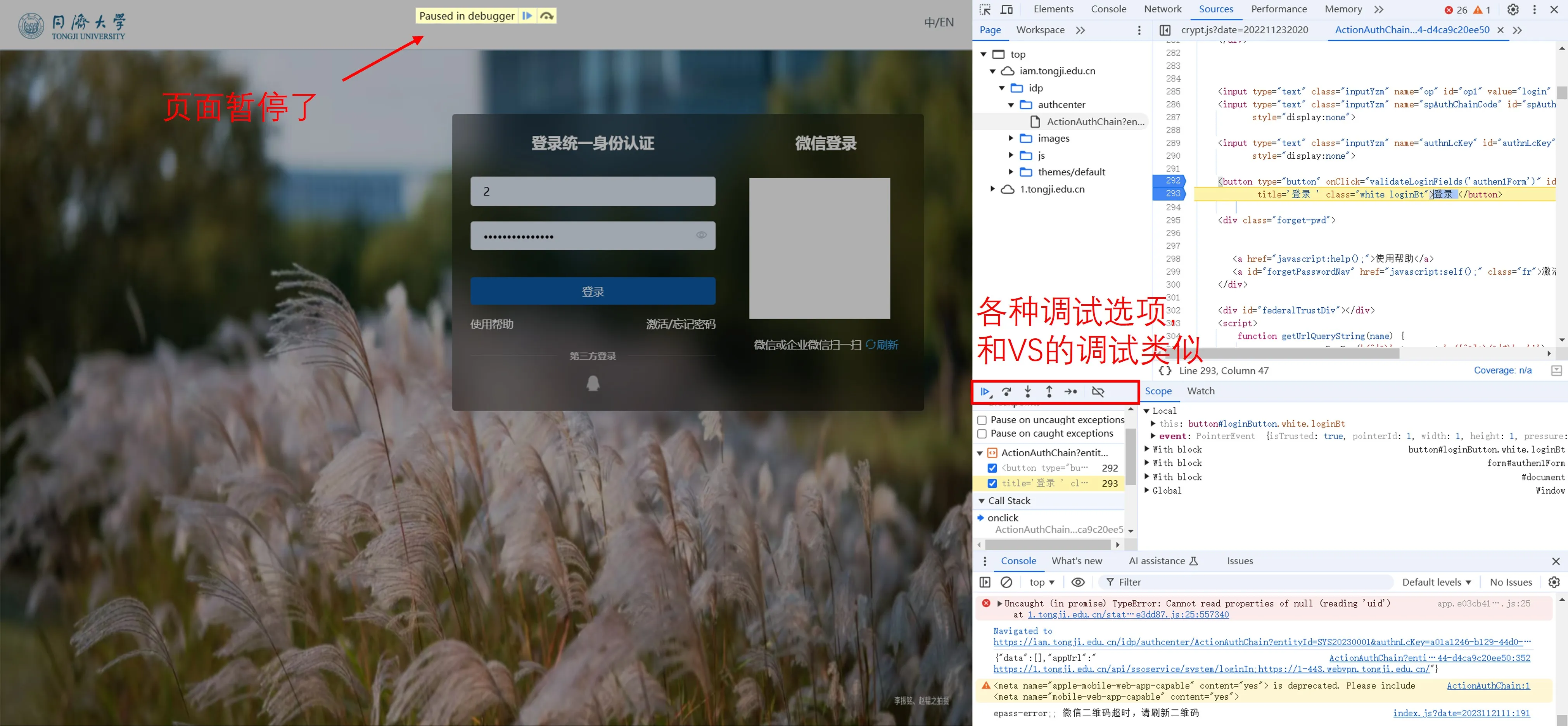
掌握了这些方法,想要获取到登录的全流程仍然比较困难:
js文件是混淆过的,不知道语句的具体含义;- 运行时函数压栈层层调用,不知道运行到了哪层,贸然跳出当前层很可能导致整个调试过程进行完毕,跳转到登录后的界面;
- 登录次数太多会触发系统的验证机制,需要额外输入验证码等。
应对这些问题,有一些小技巧,例如,把所有和网络请求有关的内容(如 ajax 等)全打上断点,布下天罗地网。或者根据文件名分析函数的功能。但不管怎么说,遇到一个新的问题需要解决时,还是要逐渐摸索。这里就略去这些摸索过程,直接给出结论。
密码加密
注意到如下函数会被调用:
1 | |
其中,message 是输入的明文密码,例如,用户输入的密码是 123456,传入的就是 123456。
经过了 JSEncrypt 库 的加密后,会返回加密后的 encrypted,然后发送给后端。具体的逻辑在 doSubmit 函数中。
1 | |
在发送的数据中,最难获取的就是加密后的密码,其他字段比较容易获得,留作习题。
发送完密码后,https://iam.tongji.edu.cn/idp/authcenter/ActionAuthChain?... 会返回 200 OK,进入后续步骤。
一条龙服务
200 OK 的状态码并不会重定向浏览器的页面,因此在后续使用 requests 来模拟请求时,需要手动请求后续页面。不过,找到第一个需要请求的页面就好啦,因为后面是一堆 302 重定向。
先向 https://iam.tongji.edu.cn/idp/AuthnEngine?... 发送 POST 请求,把刚刚发送的内容再发送一遍。
如果成功了,我们会在响应头的 Set-Cookie 字段获得 _idp_session 这一 Cookie,并被 Location 字段中的位置重定向到 https://iam.tongji.edu.cn:443/idp/profile/OAUTH2/AuthorizationCode/SSO?...。
在这里,我们会获得 _idp_authn_lc_key 这一 Cookie,并重定向到:https://1.tongji.edu.cn/api/ssoservice/system/loginIn?...。
现在来到了 1 系统的地盘。
在这里,我们会获得一个 demoState 的 Cookie,没什么作用。我们会被继续重定向到:http://1.tongji.edu.cn/ssologin?token=xxx;uid=xxx;ts=xxx。
在这里,我们会被重定向到 https 的链接(上面的链接是 http),这样,登录结束,不再被重定向了,返回 200 OK。
叙述的有些繁琐,不过,实际的登录就是这样的一个过程。
目前为止还没有结束,因为通过观察获得消息通知的请求头(见后续章节),有一个 sessionid Cookie 还没有获得。
注意到会有一个 POST 请求会被发送到 https://1.tongji.edu.cn/api/sessionservice/session/login,携带的数据是:
1 | |
这三个内容在上一步的链接 http://1.tongji.edu.cn/ssologin?token=xxx;uid=xxx;ts=xxx 中可以获得。
到此为止,登录工作已经分析完成了,接下来需要用 requests 来模拟。
requests 模拟登录
代码细节参见 fetchNewEvents.py 中的 login() 函数。
—– 第一步:登录前页面 —–
关键:从 URL 中提取 authnLcKey。
—– 第二步:ActionAuthChain —–
关键:获取 RSA 公钥,加密密码。从 js 中获得写死的 spAuthChainCode。整合数据,发送。记得修改请求头,需要添加 Content-Type 和 Content-Length。
第二步就是上面提到的容易忘记的一步。
—– 第三步:AuthnEngine —–
关键:再次发送一遍刚刚的内容。
—– 第四步:SSO 登录 —–
关键:需要更新 headers,刚刚加上的两个字段不要了。
—– 第五步:LoginIn code & state—–
—– 第六步:ssologin token—–
—– 第七步:转 HTTPS —–
源代码这里获取了 AES 公钥的链接,因为存储 AES 公钥的 js 文件名在这个页面的返回内容中可以提取到。
—– 第八步:login —–
关键:把 token、ts 和 uid 发送出去。
requests 获取通知内容
观察到 1 系统获取通知内容用到了两个方法:findMyCommonMsgPublish 和 findMyCommonMsgPublishById。不管是哪个方法,都需要如下两个 Cookie:
1 | |
第一个比较好获得,只要访问 1 系统就可以,第二个就是前面在最后一步获得的 Cookie。
这两个方法获取到的内容分别是这样:
findMyCommonMsgPublish
1 | |
方法为 POST。
这一方法会返回当前页面范围内的所有通知,但是不会返回内容和附件。因此,把 pageSize_ 开大一点,获取所有的通知数,然后再逐个获取细节即可。
findMyCommonMsgPublishById
1 | |
方法为 GET。
链接携带了 id 和时间戳,但其实只携带 id 就够了。
内容的获取比较简单,先获取所有的通知,然后再逐个遍历即可。当出现新通知的时候,发送邮件提醒。此外,需要判断这条通知有没有记录过,否则会做多余的工作,涉及到数据库的部分。
因此,接下来依次叙述邮件服务的建立以及数据库表格的设置。
附件的下载
1 系统中附件的下载并不是简单地用 <a></a> 标签存放文件地址,而是通过一个 js 动态生成的。
具体的原理是,把附件的 fileLacation 的值(我没打错,就是 FileLacation)经过 AES 加密,获得目标链接即可。AES 加密用到的是 Crypto-JS 库。
邮件通知
如果不想用属于自己的域名发送邮件提醒,用 QQ 邮箱、163 邮箱,甚至是同济邮箱就足够了(现在想想,同济邮箱甚至可达性更高一些,不过似乎没有 SMTP 功能呢)。
建立自己的邮件服务,有两个方案:自己搭建或者使用企业邮箱。这篇文章写的很不错,只不过一开始我不信邪。
自己搭建
我在服务器上采用 Dovecot 和 Postfix 搭建了一个简陋的邮件服务器,也做好了域名解析。然而,因为服务器商一般不会开放 25 端口,也就是 SMTP 服务器端口,用来发送邮件。所以在测试的时候,只能接收到其他邮箱 发来 的邮件(POP3 / IMAP),而无法对外发送邮件。
因此找到了一些邮件转发服务,如亚马逊 SES。不过,可能对方觉得我的资质不够,没能通过我的申请。
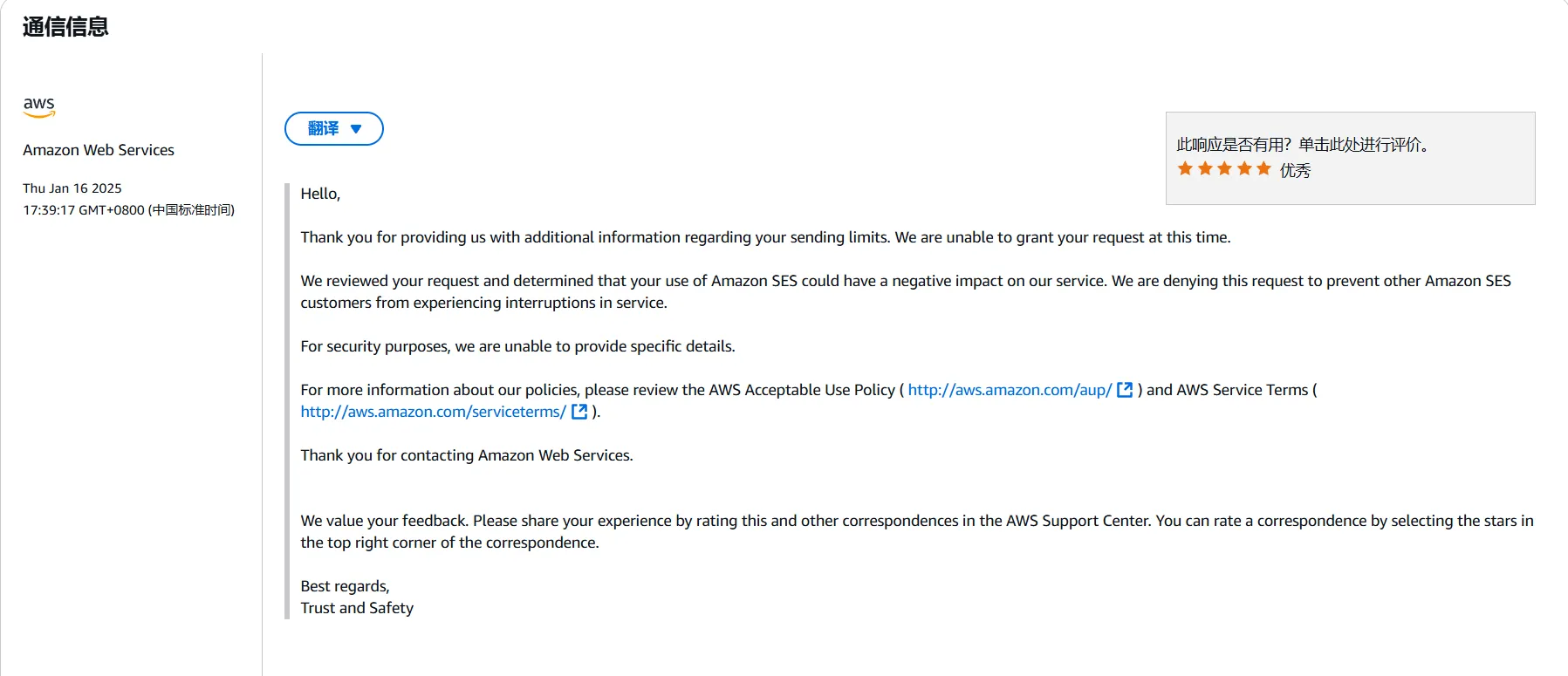
所以这条路走不通啦!我在寻觅下一个邮件转发服务商的过程中想起来了上面那篇被我嗤之以鼻的文章,于是申请了一个阿里云的企业邮箱。
企业邮箱
申请的方法很简单,最大的困难可能就是一个自己的域名了。我估计乌龙茶的大哥也是这种做法吧。因为很简单,所以不赘述了。
数据库的配置
使用的是免费的 MySQL 作为数据库。数据库表格的设置是这样的:
通知表(notifications)
| 关键字 | 类型 | 描述 | 补充说明 |
|---|---|---|---|
| id | INT | 通知的唯一标识符 | 和 1 系统数据库中的一致 |
| title | VARCHAR(500) | 通知的标题 | |
| content | LONGTEXT | 通知的内容(HTML) | 用 LONGTEXT,不然存不下 base64 的图片 |
| start_time | DATETIME | 通知的发布时间 | 用 DATETIME 而不是 TIMESTAMP… |
| end_time | DATETIME | 通知的下架时间 | …是因为 DATETIME 不考虑时区… |
| invalid_top_time | DATETIME | 什么时候停止置顶 | …不过主要还是因为和 1 系统的一致 |
| created_id | VARCHAR(45) | 发布人的工号 | 不能用 INT,否则存储不了 admin,且 0 开头的工号会略去首 0 |
| created_user | VARCHAR(45) | 发布人的姓名 | |
| create_time | DATETIME | 通知的创建时间 | |
| publish_time | DATETIME | 通知的发布时间 |
附件表(attachments)
| 关键字 | 类型 | 描述 | 补充说明 |
|---|---|---|---|
| id | INT | 附件的唯一标识符 | 和 1 系统数据库中的一致 |
| file_name | VARCHAR(500) | 附件文件名 | json 中的 fileName |
| file_location_remote | VARCHAR(500) | 在学校服务器的路径 | json 中的 fileLocation |
| file_location_local | VARCHAR(500) | 本地的存储路径 | 不包含前缀地址,即 config.ini 中的 Storage.path |
通知和附件的关系表(relations)
| 关键字 | 类型 | 描述 | 补充说明 |
|---|---|---|---|
| id | INT | 主键 | 它的数值不重要 |
| notification_id | INT | 存放通知 | |
| attachment_id | INT | 存放附件 |
因为通知和附件是典型的多对多关系(不设置成一对多是为了防止一个附件被多个通知引用,毕竟名字都叫 commonAttachmentList 了)。
到此为止,我们就把 1 系统的数据爬取到了本地,并且形成了有序的组织结构。接下来对这些数据再次处理,展示到页面上。
跳板机
因为服务器在国外(不需要备案),但是总是用国外的 IP 登录学校的系统也不是个好事,正好国内有台上海的服务器,利用起来。
使用 ssh 新建一个 socks5 代理
1 | |
-f 表示放入后台,-N 表示不执行任何命令,-D 指明了端口号,-i 指明了私钥的位置。
之后再在脚本中使用 pySocks 创建一个代理就好了。
或许是掩耳盗铃吧。
Web——数据展示
数据展示的网站编写采用的技术栈是:
- 前端:
vue3 - 后端:
flask - 数据库:
MySQL
数据库
先说数据库,因为后续可能会用到其中的表格信息:
用户表(users)
| 关键字 | 类型 | 描述 | 补充说明 |
|---|---|---|---|
| id | INT | 主键 | |
| username | VARCHAR(100) | 昵称 | |
| VARCHAR(100) | 注册邮箱 | ||
| password | VARCHAR(100) | 加密的密码 | |
| created_at | DATETIME | 注册时间 | |
| receive_noti | BOOLEAN | 是否接收通知提醒 |
登录记录表(login_logs)
| 关键字 | 类型 | 描述 | 补充说明 |
|---|---|---|---|
| id | INT | 主键 | |
| user_id | VARCHAR(100) | 用户 id | 外键 |
| ip_address | VARCHAR(100) | 登录 IP | |
| login_at | DATETIME | 登录时间 |
后端
先说后端,因为后端比较复杂。
前文说过,计科导的网站大作业并没有用户系统,所以这次我就想做一个比较完备的用户系统,估计也只会做这一次了,因为太麻烦。
接下来按功能模块来阐述后端的任务。
用户注册
新用户需要先用邮箱注册,为了数据安全,只接收同济邮箱(@tongji.edu.cn)。
如果用户的邮箱正确,则随机生成一个六位验证码。此时会生成一个和用户对应的 session,这样,后续就可以判断用户输入的验证码是否正确了。否则,万一同时有一堆人注册,怎样区分哪个验证码是哪个用户的呢?生成 session 是通过 flask_session 来的。
存储 session 使用 redis 数据库,而不是存在内存中,这样做有两个好处:
- 使用
gunicorn部署服务时,多线程下可以正常工作; - 服务重启后,
session仍然存在。
验证码正确,用户就注册成功了。把用户信息写入数据库。这里需要提一嘴密码的处理。明文密码很不安全,因此采用 argon2 加密。数据库中存储的密码长这样:
| id | nickname | password | created_at | receive_noti | |
|---|---|---|---|---|---|
| 3 | cirno | cirno@tongji.edu.cn |
$argon2id$v=19$m=65536,t=3,p=4$mzAj2HA19xJ+3AYe2tLfuw$w1S8Zj885OvJTi6PMIM4B/5tAmXpDScd9+i2AfKzvEI |
2025-01-23 14:19:16 | 1 |
默认的 receive_noti 为 0。也就是说,如果用户想要接受邮件提醒,需要手动设置,这样可以避免不必要的打扰。
用户登录
登录只支持邮箱+密码的登录方式。
传入的密码经过了 RSA 加密的,和 1 系统的处理方式一样。上文用户注册,下文忘记密码中传送的密码也都是加密过的。RSA 是一种不对称加密。就算在 js 中的公钥被人所知也没关系,因为只有私钥才能破解原来的内容。但相对地,AES 加密就是一种对称加密,只有一把钥匙。因此最好不要用 AES 加密来加密密码。
后端解密密码使用的是 Cryptodome 库。
每一次登录,后端会记录登录的 IP 地址和登录时间,写入 login_logs 中。获取时间很简单,如何获取 IP 呢?因为后端服务是使用 nginx 反向代理的,无法直接获得客户端 IP,只能直接获得本机 IP,也就是 localhost。实现的方法是通过 X-Forwarded-For 头部,通过配置 nginx,这一头部会返回一连串的转发 IP,最开始的就是用户的 IP。当然,我现在看到的 IP 还会多一层,因为除了本机的 nginx 一层代理之外,Cloudflare 也有一层代理。
忘记密码
如果忘记了密码,就再发送一封邮件到邮箱,接收验证码,输入新密码,和注册的流程类似。
获取通知
获取通知的简略内容。从数据库中 SELECT * 就好啦。
而获取通知的细节内容,只需要针对传入的通知 id,在数据库中查询即可。
下载附件,则是打开本地文件,返回二进制数据。
从叙述中可以看出来,如果手中有了数据,想展示出来是很容易的。然而如果想要爬取别人的数据,就需要费许多功夫了。
凭证的管理
其他的一些简单方法就不赘述了,最后提一句关于用户登录状态的管理。
使用 flask-jwt-extended 实现登录凭证。如果登录成功,会发送一个 xl_token 和 csrf_access_token,后者是为了防止一种攻击而设置的,每次在请求头中请求时需要手动加到 headers 里。
每一个需要登录后才能访问的 api 加上一个 @jwt_required 装饰器就好了。
登出的时候要清除发放的凭证,使用 unset_access_token 来实现。
前端
前端使用 vue3 的 optionsAPI 形式来实现,使用了 Element Plus 组件库,1 系统同款。
先按页面叙述,最后再说说用的非平凡的技术有哪些。
登录前页面
很朴素的登录页面。
首页
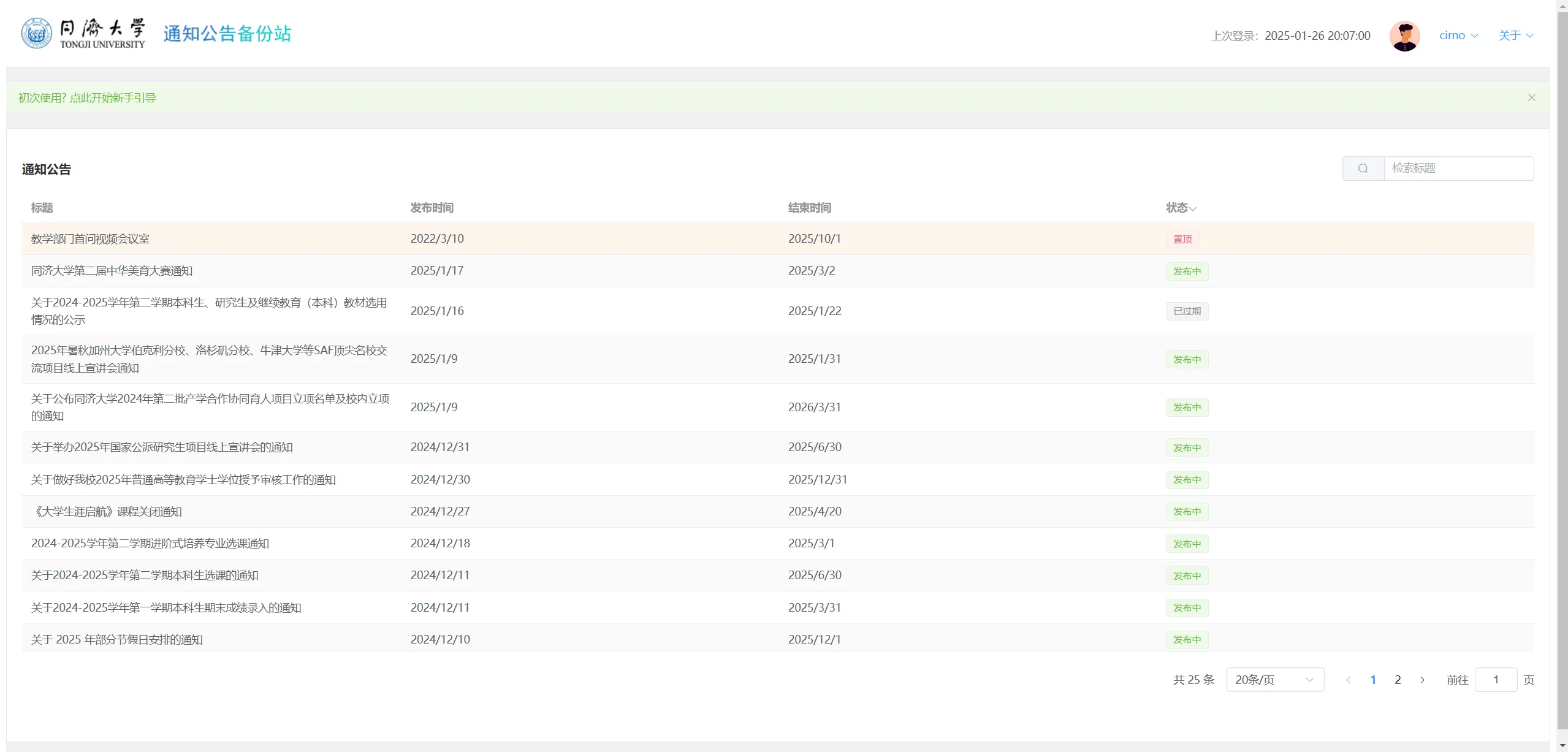
这个页面可以说一说。
页面右上方有两个下拉菜单。昵称所在的下拉菜单可以维护个人信息和退出登录;关于所在的下拉菜单指向 Github 仓库。
绿色的提示条,点击后会开启一个新手指导。
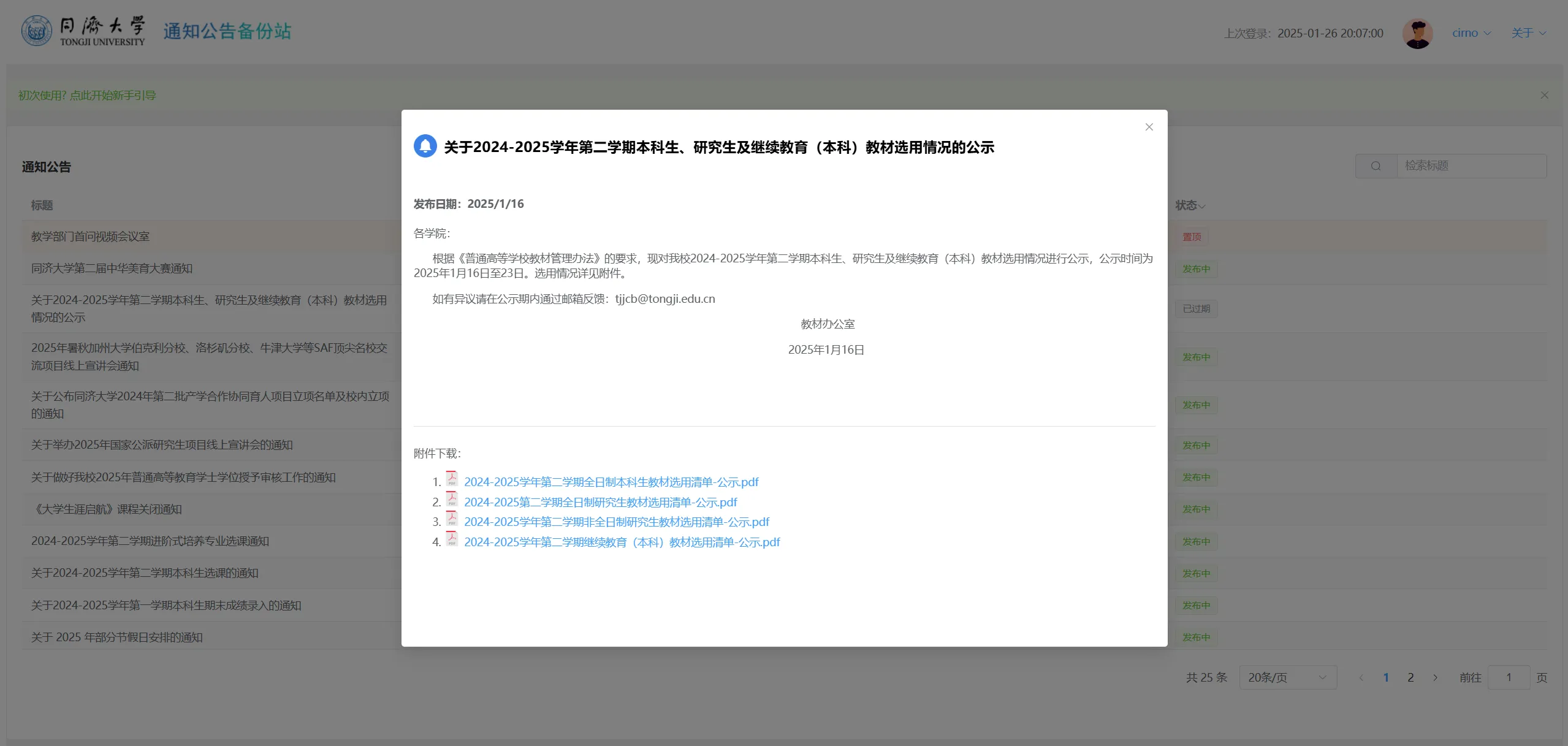
表格展示了通知的信息,状态列表头旁的下箭头可以筛选通知公告的状态。表格的每一行都是可以点击的,点击后会弹出通知的详细信息,如下:
个人信息维护
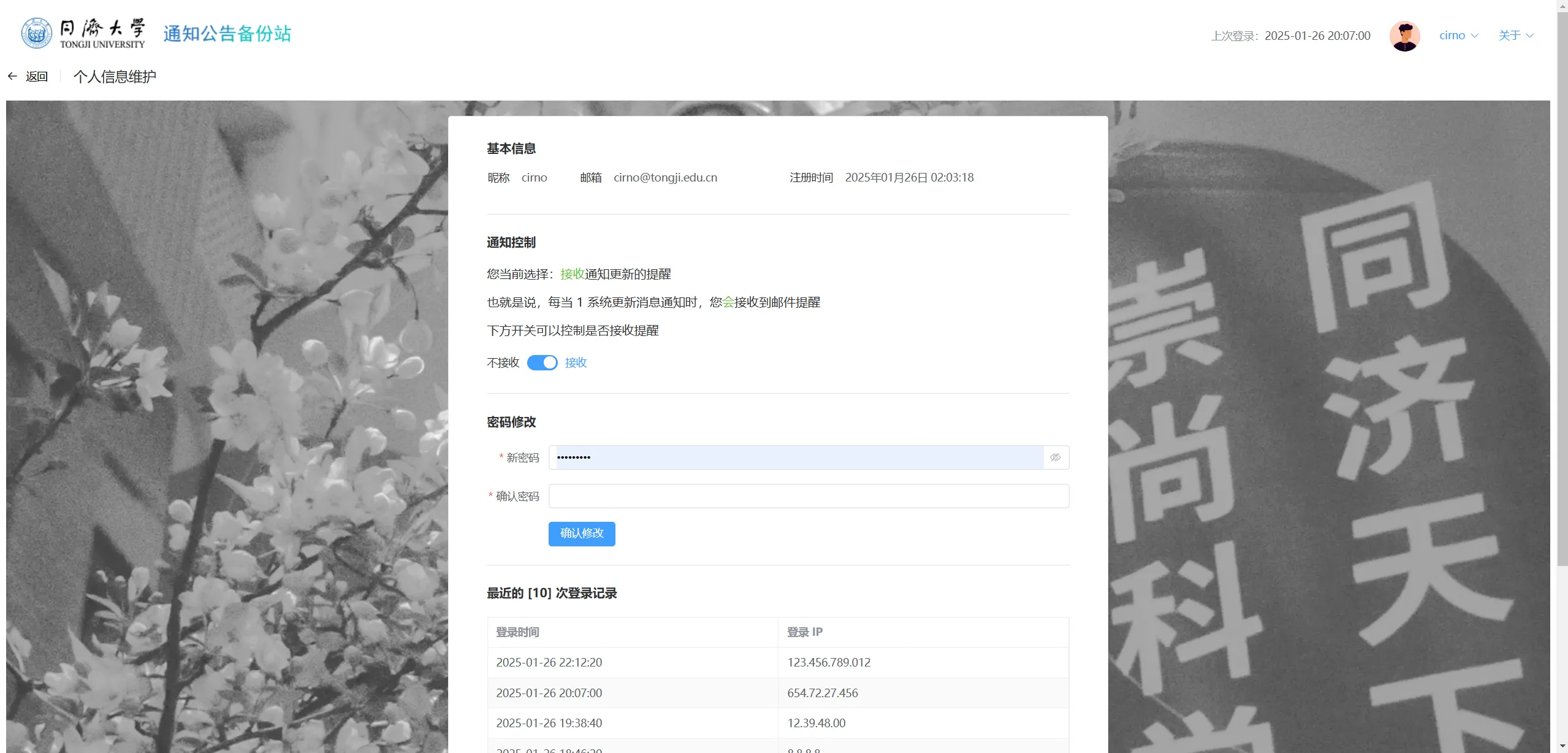
在个人信息界面,可以查看基本信息,控制是否接收通知,修改密码,以及查看最近的几次登录记录。
vue router——页面跳转
使用 vue-router 实现页面跳转,值得说明的是,对于一些登录后才能访问的界面,可以在 beforeEnter 中进行设置,只有登录后才能进入对应页面,否则会跳转到 login 界面。反之,如果已经登录过了,则在访问登录、注册等页面时会跳转到根目录。
比如:
1 | |
vuex——状态存储
使用 vuex 来进行状态的存储,状态的变换要使用 mutations,有点像数字逻辑的有限状态机。还有一些更复杂的方法,项目没有涉及到。
需要注意的是,如果单纯地使用 vuex 来存储状态,由于状态在内存中存储,所以刷新页面或者打开的新页面并不会保留先前的状态,因此需要把状态存储到 localStorage 或者 sessionStorage 中。
PS
仿照 1 系统做的 logo,只需要新建一个渐变色的矩形。之后创建剪切蒙版就好了。
个人信息维护的背景界面,是调整为灰度后,加了干画笔滤镜、调整色阶得到的。
部署
网站还是要部署到服务器上才好。
服务器是利用学生优惠白嫖了一年的 DigitalOcean 服务器,系统为 Ubuntu 24.04 LTS,地理位置在新加坡,这样不用备案,比较方便。
Python 环境配置
和本地的配置环境类似,用
1 | |
新建一个虚拟环境。
再使用
1 | |
和本地的 .venv/Scripts/activate 略有不同。
之后再安装包就可以了。
DNS 解析
使用裸 IP 访问很不好,需要使用域名来解析到 IP。如果有域名的话,添加一条 DNS 解析的 A 记录,指向服务器的 IP 就好了。
SSL 证书
使用 https 比较安全,因此需要申请证书。我的域名在腾讯云注册的,在那里申请的免费证书。
Nginx
就像客户端访问网页需要浏览器一样,服务器也需要软件来提供 Web 服务,常见的有 Nginx 和 Apache,我这次试了试后者,感觉好像不是很好用,所以还是用回了熟悉的 Nginx。
Nginx 的配置还算可以理解。网站的配置文件放在 /etc/nginx/sites-available 下,如果要启用这一网站,则在 sites-enabled 下使用 sudo ln -s xxx 创建一个符号链接即可。一个典型的 server 块长这个样子
1 | |
root 应该指向要部署的网站,这里的 dot 存放了 vue 生成的前端页面。生成这一文件夹的命令是 npm run build。
location /api/ 指向了本地的后端服务,并设定了一些头部。
gUnicorn
gUnicorn 是用来部署 Flask 的。可以采用系统服务的形式来创建一个部署。新建一个 .service 文件,设定好环境和文件位置,把它放到 /etc/systemd/system 下,启动就好了。
爬虫
和网站部署没关系。爬虫也需要每日定期运行,所以这里顺带着提上一嘴。
用 cron 来实现定时任务。
1 | |
碎碎念
花了放假的两周,完成了这一个小项目。目的很单纯,一个是练习爬虫。之前爬取的图书馆网站的数据比较简单,因为不需要登录。这次爬一个难度大的。再一个是练习用户管理。最后,或许是为了做一个类似于上大的排课助手做准备?也许会做吧,太累了。
总结这次项目,花了两三天研究明白了统一身份认证,花了两三天模拟了爬虫,登录成功。再花了一周左右设计了数据库表格,写完了前后端。
虽然对自己写出来的代码不像 OOP 的大作业一样,能够说明白每一句话的具体功能,不过,写了三四个网站,确实是越来越清晰了。向前走下去吧。
致谢
感谢同济大学提供的数据与网站。
感谢印象同济的背景图片。