更新时间
课表更新的时间有三个阶段:
- 上学期
16 周左右的第一轮选课前夕;
- 下学期开学后第四轮选课结束,教务处发布某些选修课调整关停的通知后;
- 下学期期中退课结束后。
更新流程与方法
在个人电脑上
记得备份!记得备份,记得备份!
Excel 表格
访问 1.tongji.edu.cn,切换到全校课表,把对应学期的全校课表导出为 Excel 表格;
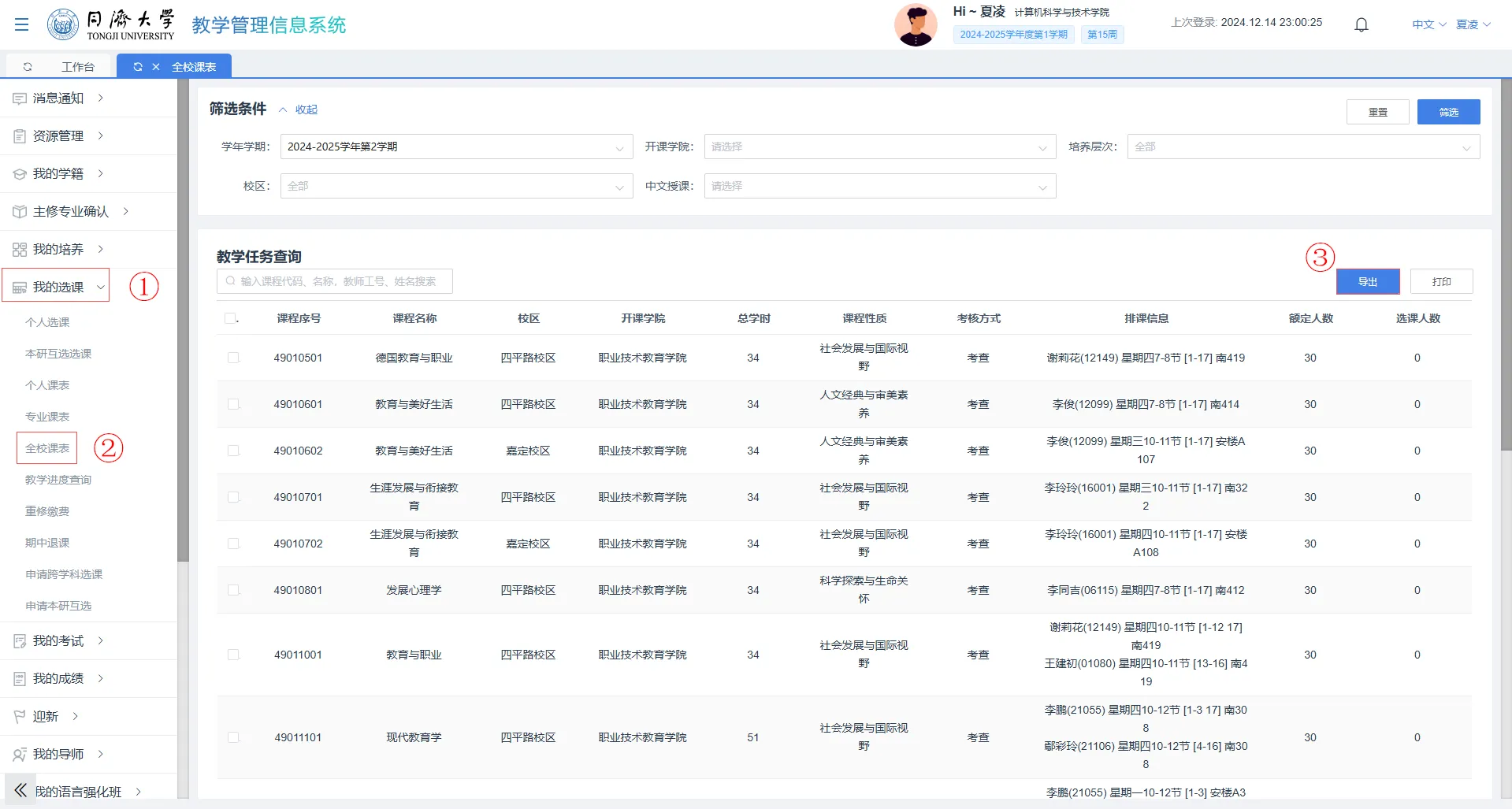
导出为 .csv
把 Excel 表格导出为 .csv 文件;
方法:文件->另存为->选择位置->在下拉菜单选择(.csv)->保存
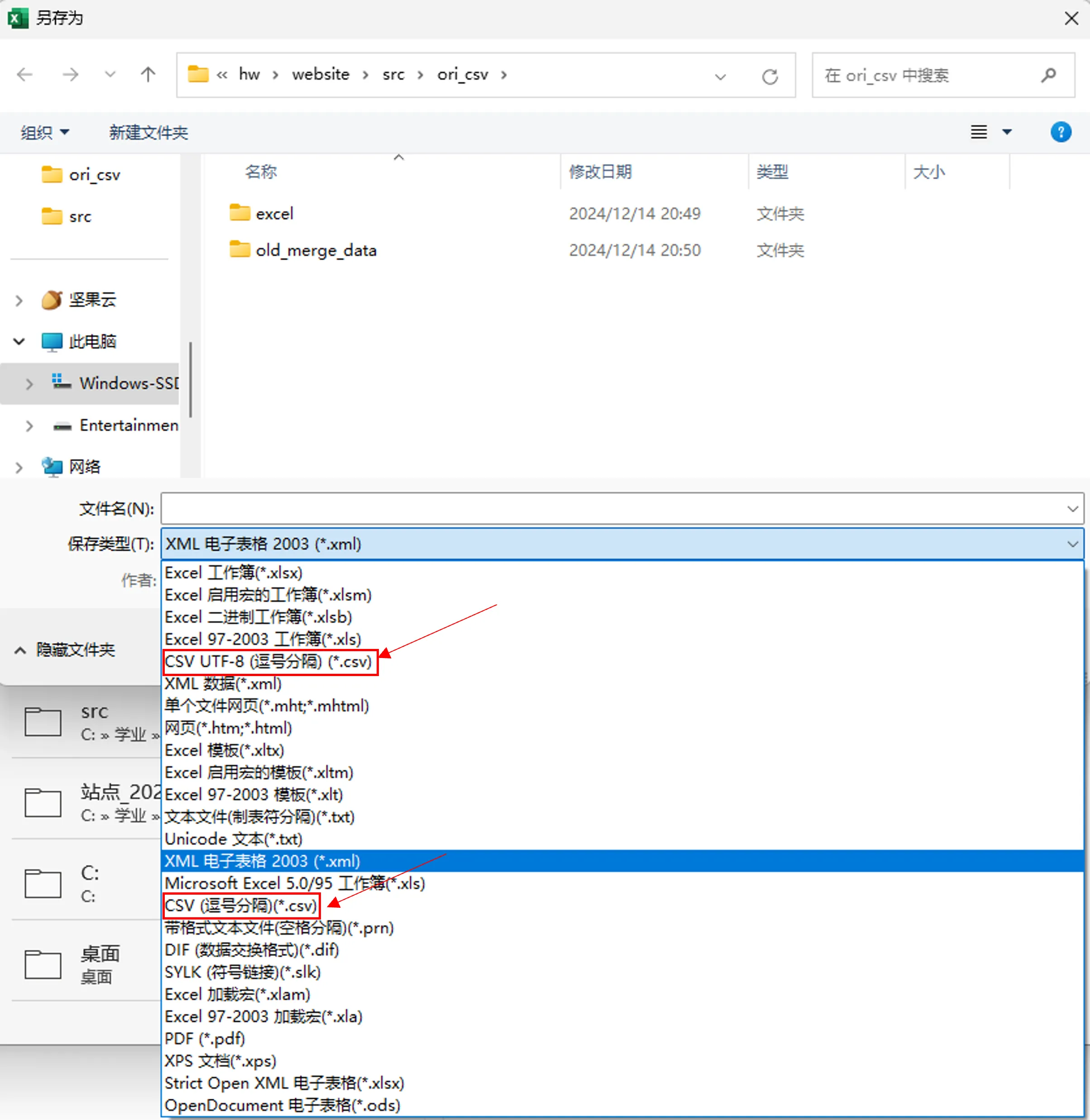
这两个有什么区别吗?如果选择不含有 UTF-8 的(靠下面的),编码会变成 GB2312,在进行 pandas 处理的时候会有问题,提示无法读取对应编码(因为 pandas 默认读 UTF-8),然而如果在 python 程序中指定 coding 似乎也无法解决问题,所以这时,可以通过 VSCode 打开 .csv 文件,先选择 按编码打开,GB2312;再选择 按编码保存,UTF-8 with BOM,解决!至于说没有 BOM 的单纯 UTF-8 怎样,以后可以试试..
进行数据处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
import os
import pandas as pd
import time
csv_files = [f for f in os.listdir('./ori_csv') if f.endswith('.csv') and '学年' in f]
print(csv_files)
edited_files = [f for f in os.listdir('.') if f.endswith('_edited.csv')]
print(edited_files)
csv_files = [f for f in csv_files if f.replace('.csv', '_edited.csv') not in edited_files]
print(csv_files)
processed_dfs = []
for file in csv_files:
semester = file.split('工作安排表')[0]
ori_path = './ori_csv/'
df = pd.read_csv(ori_path + file, skiprows=2)
if "负责人" in df.columns:
df = df.drop(columns=["负责人"])
df['开课学院'] = ''
current_department = ''
skip_next = False
for i, row in df.iterrows():
if skip_next:
skip_next = False
continue
if pd.isna(row.iloc[1]) and isinstance(row.iloc[0], str):
current_department = row.iloc[0].strip()
skip_next = True
elif pd.isna(row.iloc[0]) and pd.isna(row.iloc[1]):
current_department = ''
skip_next = True
else:
df.at[i, '开课学院'] = current_department
df = df.dropna(subset=[df.columns[1]])
df.insert(0, '学期', semester)
df = df.map(lambda x: x.rstrip() if isinstance(x, str) else x)
df = df.map(lambda x: x[:-1] if isinstance(x, str) and x.endswith('\r') else x)
df = df.reset_index(drop=True)
processed_dfs.append(df)
for i, df in enumerate(processed_dfs):
df = df.map(lambda x: x[:-1] if isinstance(x, str) and x.endswith('\r') else x)
processed_dfs[i] = df
new_filename = file.replace('.csv', '_edited.csv')
df.to_csv(new_filename, index=False, header=True)
if processed_dfs:
merged_df = pd.concat(processed_dfs, ignore_index=True)
if os.path.exists('merged_schedule.csv'):
existing_df = pd.read_csv('merged_schedule.csv')
merged_df = pd.concat([existing_df, merged_df], ignore_index=True)
merged_df.to_csv('merged_schedule.csv', index=False, header=True)
print("处理完成,所有文件已保存并合并为 merged_schedule.csv")
else:
print("没有找到需要处理的文件或所有文件已处理过。")
|
现在的处理逻辑是:
- 先查找有没有新的课程表添加进来;
- 对新添加的课表进行处理,生成
*_edited.csv 文件;
- 读取原来的
*merged.csv 文件到内存中,把新课表 append 到后面。
- 保存为新的
*merged.csv 文件。
所以注意,在进行新学期的添加前,记得备份!记得备份,记得备份!否则就被覆盖了。
这里的备份指的是把原来的 *merged_csv 复制一份,而不是剪切,不然又乱了。
导入到数据库
其实你说,真的有必要生成一份 *merged.csv 文件吗?没必要。只需要把新学期的课程 LOAD 到课表里就行了。不过为了保险,还是存一份原始 .csv 文件吧,方便迁移?或许。
导入到数据库,除非哪天数据库不小心被我删了,否则只需要插入更新的一个学期的内容就可以了,当然现在还没有经历过第一部分说的两个步骤,后续如果需要修改某学期的内容,需要先把对应学期的内容删除掉(否则会有主键重复),到时候再更新这篇文档。
导入到数据库的原始代码如下:
1
2
3
4
5
6
| LOAD DATA INFILE '/path/to/24252.csv'
INTO TABLE course_all
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES;
|
把表格导出为 .sql 文件,迁移到服务器
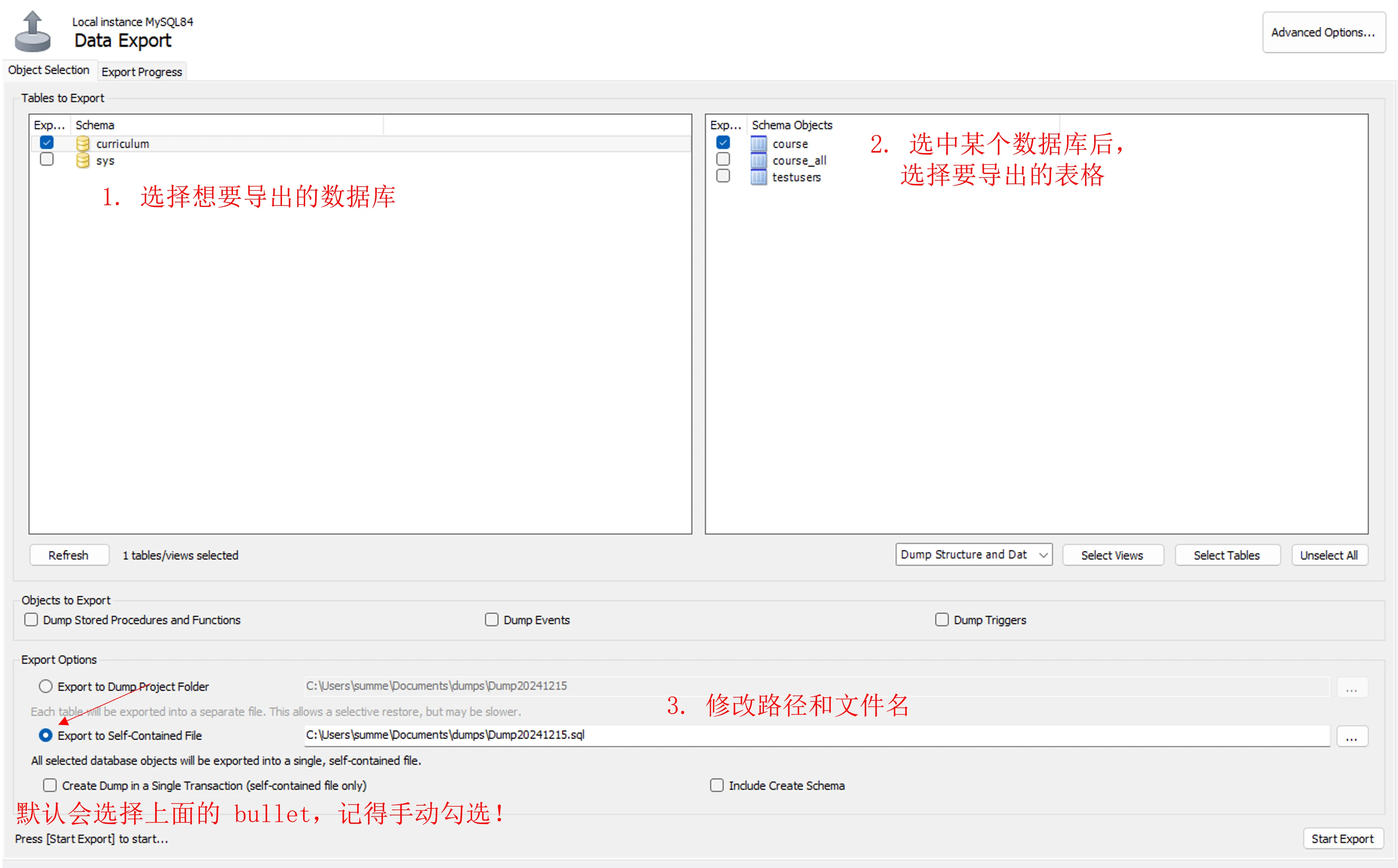
这样就得到了 .sql 文件。
本地测试
打开 vue 服务的方法是 npm run dev。
打开 flask 后端的方法是 flask run --port=8000,因为我用的是 8000 端口。
在服务器上
使用 XSHELL 连接到服务器
oop 已经使用过很多次了,不赘述。
把 .sql 文件通过 XFTP 上传到对应文件夹
和本地的配置不同,服务器上 app.py 的配置体如下:
1
2
3
4
5
6
7
| db_config = {
'host': 'localhost',
'user': 'zhangsan',
'password': '******',
'database': 'ABCDE',
'charset': 'utf8mb4',
}
|
这样可以确保安全,使得后端访问数据库的时候只能读,不能写。这里只是说一句,重点在于,把 .sql 导入到数据库后,对应的 DATABASE 名和 TABLE 名要对应,不然查找不到东西!
如果存在某个 <database>,直接运行:
1
| sudo mysql your_database_name < /path/to/your_file.sql
|
即可。
换句话说,就是不需要进入到 mysql 进程当中。如果不小心进入了,输入 EXIT; 来退出吧!
如果对应的 <database> 不存在,需要手动创建。这时候需要进入 mysql 进程,进行如下操作:
语法应该没错。创建完就 OK 了,可以导入。不用新建表格,设计表的结构,因为直接导入来的 .sql 文件包含了这些信息。(当然到目前为止,这部分内容是我凭空揣测的,等遇到实际应用时再修正)。
重启服务
有一个 rfs 别名,可能是 Restart Flask Service 的意思吧,忘了具体含义了。别名对应关系是:
1
| rfs='sudo systemctl restart nginx; sudo systemctl restart flask_app.service'
|
那这个 flask_app.service 是啥呢?它是一个系统服务,在我的服务器上存放在 /etc/systemd/system 下,内容是:
1
2
3
4
5
6
7
8
9
10
11
12
| [Unit]
Description=Gunicorn instance to serve Flask application
After=network.target
[Service]
User=ubuntu
Group=www-data
WorkingDirectory=/home/ubuntu/jkd-web/flask-backend/
Environment="PATH=/home/ubuntu/jkd-web/flask-backend/venv/bin"
ExecStart=/home/ubuntu/jkd-web/flask-backend/venv/bin/gunicorn -w 4 -b 127.0.0.1:8000 app:app
[Install]
WantedBy=multi-user.target
|
这段代码完全是 AI 生成的,现在我几乎看不懂了。以后写大作业的时候一定要留一份文档,给自己看也好。
结束..之前
执行到此,应该可以正常在 tongji.xialing.icu 中查询到最新的课程了!这次更新也说明了:我的网站可以自己定位到最近的学期进行选择,很方便。
更新日志
- 在主页更新本次更新的内容和时间;
- 在
footer 更新本次更新的时间。
