
汇编语言学习总结
本文章是学习王爽老师的《汇编语言 第三版》积累的笔记,不可以代替原书,只是起到总结的作用。如果要入门汇编,还是要看王爽老师的教材,阅读完毕后,可以阅读本文章,查漏补缺。
寄存器
通用寄存器
AX
AX经常被用于中转,和运算相关。例如,要修改段寄存器的值,不可以使用MOV, 立即数,必须将立即数先存到AX中,再转移到段寄存器中。常见的一个用法是:
1 | ; 代码的作用:将数据段地址设置为1000h |
关于其在加减法、乘除法的作用,参见DX部分。
BX
BX和地址相关。如果要通过寄存器间接寻址,AX,CX,DX这三个通用寄存器在语法不支持,必须使用BX,这是8086硬件导致的。BX间接寻址的用法如下:
1 | MOV BX, 1000h |
BX默认的数据段是DS,也可以使用ES:[BX]进行段跨越。8086中,物理地址的构成是段地址+偏移地址,这里BX储存的就是偏移地址,构成真正的物理地址,要进行下列运算:例如(DS)=1000H,(BX)=0010H,则物理地址(PA)=10000+0010=10010H。
BX常用在循环loop中,作为可以改变的偏移地址。
CX
CX常作为计数器。CX存储了多少,循环就进行多少次。所以每次在执行循环之前,都要指定CX的值。看这个简单循环:
1 | ; 作用:将FFFF:0开始的64字节空间复制到2000:0开始的空间 |
DX
DX在运算部分很有用,根据运算数的宽度,决定只使用AX或者同时使用AX和DX。就像在字母表的位置上,D比A大一样,DX一般存储结果的高位。
段寄存器
CS(IP)
CS的中文名叫指令指针寄存器,它和IP(指令指针寄存器)两个是8086最重要的两个寄存器,和指令的执行有关。注意:IP不是段寄存器,但为了方便,在这里一同介绍。
8086执行指令,按照(CS)*16+(IP)的结果来确定执行指令的地址。这个其他地址的确定方法类似,都是段地址+偏移地址的形式。上面提到的循环指令得以执行,和IP密切相关。
方法一:
要修改CS和IP,当然可以借助某个寄存器,使用MOV指令。8086大部分寄存器的值(思考:哪些不行呢。提示:段寄存器。),都可以通过MOV改变,MOV又被称作传送指令。
方法二:
可以使用JMP指令。
同时修改CS、IP的内容,使用JMP 段地址:偏移地址,如JMP 2AE3:3,执行后,CS变成2AE3H,IP变成0003H。
只修改IP的内容,使用JMP 某一合法寄存器,如JMP AX,若(AX)=1000H,则执行后,(CS)不变,而(IP)=1000H。
DS
DS是数据段寄存器,默认用来存放数据的段地址。例如,上面出现过的一个例子:
1 | MOV BX, 1000h |
此时,如果(DS)=2000H,(2100H)=03AEH,则存入AX的值为03AEH。
对于数据的访问,可以按字访问或者按字节访问。到底按哪种方式呢?
方法一:根据目标寄存器的宽度
如MOV AX, 255就是按字访问;MOV AL, 255就是按字节访问。
方法二:强制类型转换
C语言中有强制类型转换,汇编也有。如WORD PTR或者BYTE PTR,加到目的前即可。
SS(SP)
SS是栈段寄存器。在讲SS的同时,就把栈顺带说了吧。
栈就是一个杯子,SS存储栈段的段地址,SP存储栈顶指针的偏移地址。比如,如果把1000H;00-1000H:FF作为栈使用,则(SS)=1000H,在栈为空时,(SP)=100H。为什么呢,因为当进栈的时候,要先将SP的值-2,然后将一个字的数据写入内存。栈顶从高字节开始,逐渐向低字节增长。
有关POP和PUSH的作用,请参见常用指令。
栈顶当然有可能越界,这个是要人为通过高级语言来保证的。换句话说,汇编语言并不能检测栈顶越界的错误。
ES
ES又叫扩展寄存器,通常是作为扩展段来使用。比如,要从1000H:0开始,复制16个字节的内容到2000H:0。此时就可以将DS和ES分别设置为1000H和2000H,BX设置为偏移地址,进行循环操作,每次(BX)+1,便可以实现内容的复制,很方便。
地址寄存器(BX、BP、SI、DI)
和寻址有关的寄存器,有BX、BP、SI、DI四个。如果理解了各自的英文全称,就可以区分它们的功能了
| 名称 | 全称 | 用途 | 默认段 |
|---|---|---|---|
| BX | Base Register | 基址寄存器 | DS |
| BP | Base Pointer | 通常和访问堆栈有关 | SS |
| SI | Source Index | 通常作为源的变址 | DS |
| DI | Destination Index | 通常作为目标的变址 | DS(字符串操作:ES) |
BX和数据段绑定,BP和栈段绑定。而关于SI和DI,就像在段寄存器-ES部分阐述过的一样,对于字符串的复制,使用SI和DI很方便。那他们当然默认的段就是DS和ES了啊!但是对于一般的内存访问,DI的默认段寄存器还是ES。
标志寄存器
标志寄存器和其他寄存器不同,它每个位都表示各自的含义,组合起来的2Byte并没有含义。下面介绍几个常用的标志,这些标志了解即可,因为后续我们不需要对标志进行操作,只需要在逻辑上调用使用了这些标志的指令即可。
ZF标志
零(_Zero_)标志位。如果指令执行后的结果为0,则zf=1,否则为0。
PF标志
奇偶(_Parity_)标志位。如果结果的所有bit位1的个数为偶数,pf=1,否则位0。
SF标志
符号(_Sign_)标志位。对有符号数而言,如果结果为负,则sf=1,否则为0。和补码的符号位是不是很相似?
CF标志
进位(_Carry_)标志位。对无符号数而言,如果结果有进位,则cf=1,否则为0。
OF标志
溢出(Overflow)标志位。如果有符号数超过了机器可以表示的范围,则of=1,否则为0。什么叫溢出?什么叫超过表示范围?例如:
1 | mov al, 98 |
得到的结果197无法在8位寄存器中正确表示,因为al的表示范围是-128~127。因此,最终得到所谓的98+99=-59,这是不可接受的。
注意:SF、CF、OF的改变,和逻辑上正在进行哪种运算无关。比如上面的例子,假设逻辑上我们在执行无符号运算,按理说,我们不在乎SF和OF的值,但是SF和OF也可能改变。换句话说,对于机器而言,它操作的数据就是一串二进制数据,得到的结果也是一串二进制数据。在操作过程中和得到的结果中,根据有符号和无符号的两种理解方式,修改标志的值,与人对于数字的理解无关。
DF标志
方向(_Direction_)标志位。在串处理指令中,控制每次操作后si、di的增减。和它有关的指令为:
std,_Set Direction_,将df=1,递减;cld,_Clear Direction_,将df=0,递增。
TF标志
陷阱(_Trap_)标志位。(tf)=1时,单步调试。
IF标志
中断允许(_Interrupt Enable_)标志位。当(if)=1时,是不可屏蔽中断;否则为可屏蔽中断。
常用指令
MOV
MOV叫传送指令,就是把源的值赋给目标。
ADD
ADD是简单加法,很简单。
用法:ADD AX, BX,意思是把AX和BX储存的值相加,并把结果储存在AX中。
可以看出,寄存器中存的内容,到底是当做值,还是当做地址,完全看我们用什么样的指令来操作。不同的指令,对于二进制内容会有不同的理解方式。
注意,两个寄存器的位数要对应,和MOV一样。
SUB
和ADD的用法类似,不赘述了。
ADC
ADC执行带进位的加法。利用CF上记录的进位值。这样,理论上可以实现无穷长度的数据的加法计算。
SBB
SBB执行带借位的减法。和ADC的原理类似,藉此可以实现对无穷长度数据的减法运算。
MUL
- 两个相乘的数,要么都是8位,要么都是16位;
- 如果都是8位,一个默认在
AL中,另一个放在8位reg或者内存单元中;结果默认放在AX中; - 如果都是16位,一个默认放在
AX中,另一个放在16位reg或者内存单元中;结果高位默认在DX存放,低位在AX中存放。
注意:
- 对于内存单元的寻址方式,需要给出数据的宽度,即需要强制类型转换;
- 注意到乘法不支持立即数。
DIV
DIV是除法指令。
- 如果除数为8位,则被除数是16位;除数在一个
reg或内存单元中,被除数默认在AX中;结果AL存放商,AH存放余数; - 如果除数为16位,则被除数为32位;除数在一个
reg或内存单元中,被除数在DX存放高16位,AX存放低16位;结果AX存放商,DX存放余数。
POP
POP用来出栈。先将内容写到目标地址,然后将(IS)+2。
PUSH
PUSH用来压栈,或者叫进栈。先将(IS)-2,然后将内容写到栈中。
可以看到,POP和PUSH只能一次修改一个字(2Byte)的内容。
PUSHF与POPF
pushf将标志寄存器的值压栈,popf将栈中的值压入标志寄存器。它们不接受参数,但可以通过修改栈的值,间接改变标志寄存器的值。
AND
AND用来执行与运算,例如,
1 | mov al, 01100011B |
的结果为:00100011B。
达成的效果是:将可操作对象的相应位(掩码为0的位)设为0,其他位不变。
OR
OR用来执行或运算,例如
1 | mov al, 01100011B |
的结果为:01111011B。
达成的效果是:将可操作对象的相应位(掩码为1的位)设为1,其他位不变。
SHL
SHL的作用是左移位,把最高位存储到CF标志中,低位补0。
SHR
SHR的作用是右移位,把最低位存储到CF标志中,高位补0。
注意:
在
SHL和SHR的使用中,如果移动的位数为1,可以使用立即数,形如shl, ax, 1;如果移动的位数大于1,则需要使用
CL存储移动的位数。
CMP
cmp指令对两个操作对象进行比较,通过比较的结果修改标志寄存器中对应的值。它通常和条件跳转指令连用。
LEA
LEA指令获得某个标签对应的偏移地址。用法:LEA BX, 标号。
SEG
SEG指令获得某个标签对应的段地址。用法:mov ax, seg datasg。
转移指令
循环
在汇编语言中使用循环,需要涉及到loop伪指令。
一般的循环结构如下:
1 | ; Basic Circulation |
进入循环之前,先给CX赋值,因为(CX)决定了循环的执行次数。
循环的标志是标号,标号开头是循环的内容,一直到loop前。
loop的执行逻辑是:
- 先将
(CX)-1 - 判断
(CX)是否不为0,如果为0,则执行loop下方语句,否则跳转到标号语句
loop通常可以和[BX]联合使用,从而方便地进行内容的复制等操作。
注意loop只能实现短转移喔!
跳转
无论哪种跳转,实现的底层逻辑都是修改CS、IP的值。
无条件跳转
无条件跳转的指令是jmp,可以只修改IP,也可以同时修改CS和IP。
jmp short s实现的是段内短转移,对IP修改的范围是-128~127,机器码中不包含转移的目的地址,而是位移;jmp near ptr实现段内近转移,对IP的修改范围是-32768~32767,机器码也包含位移;
关于位移的计算,是(目的偏移地址)-(源的下一条指令的偏移地址)。
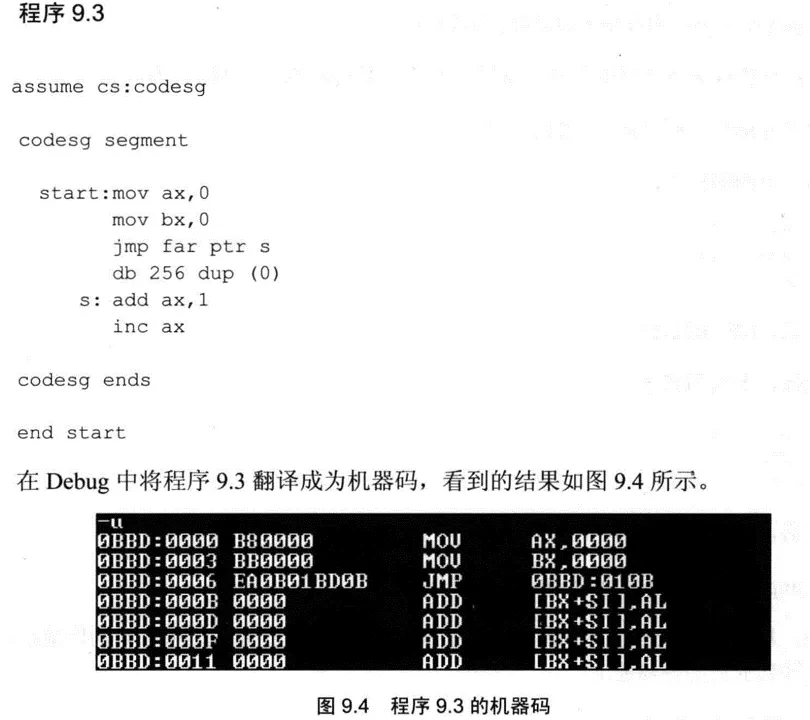
jmp far ptr s实现远转移,机器码中包含转移的目的地址。jmp 2AE3:3会同时修改CS和IP的值;jmp AX会只修改IP的值,用寄存器的值覆盖;- 如果转移地址在内存中,根据宽度的不同,也分成段内转移和段间转移
jmp word ptr 内存单元地址只修改IP的值;jmp dword ptr 内存单元地址修改CS和IP的值,CS的值在高位;
有必要对jmp short s和jmp far ptr s进行辨析。
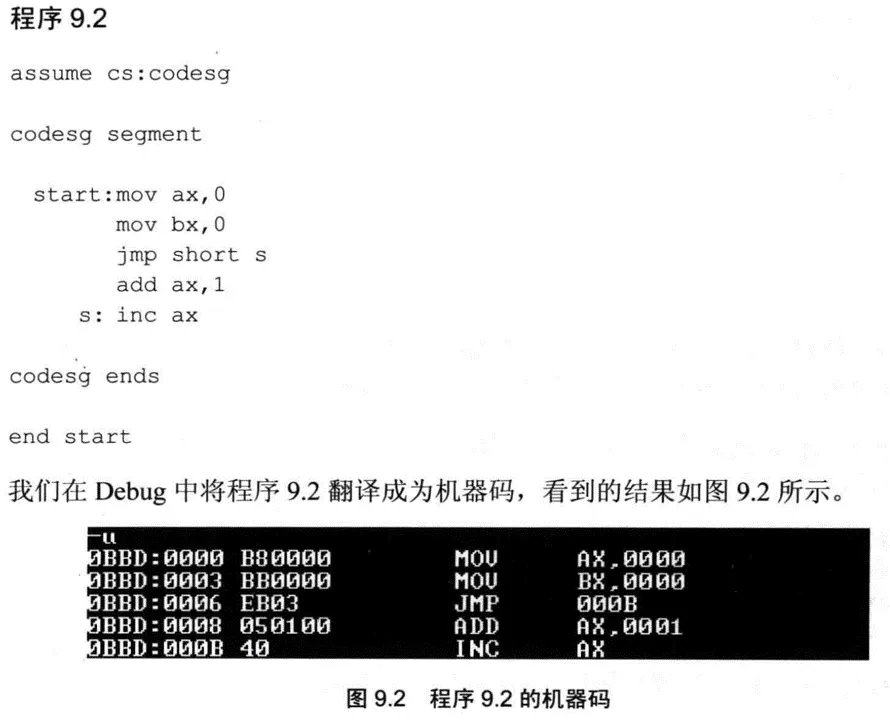
一个常考的题目是:已知机器码EB03,判断跳转的目标地址;或者已知反汇编的指令JMP 000B,判断机器码为EB??。
要指出的是,内存当中存放的是跳转的偏移量,例如03就是偏移量。那为什么不跳转到0BBD:0009,而是000B?这就要回顾指令执行的顺序:
- 从
CS:IP指向内存单元读取指令,读取的指令进入指令缓冲器; (IP)=(IP)+所给指令的长度,从而指向下一条指令;- 执行指令。转到1重复这个过程。
EB03就是根据指令中的03修改了IP的值。
读取EB03这个指令后,IP指向下一条指令,偏移地址是0008H。之后,再执行EB03,把(IP)再加3,就指向000BH啦!
反过来,如果知道指令是JMP 000B,知道JMP指令下一条指令的偏移地址是0008H,二者相减,得到的就是03啦!
但是对于jmp far ptr s来说,注意到机器码中直接包含了段地址和偏移地址。需要注意,段地址在高位置,并且在一个字中,按照高放高来安排字节的存储。谁在高位?按照最左侧一列的排布,原来一行中右侧的内容反而在高位。
条件跳转
jcxz 标号,如果(cX)=0,则跳转;loop 标号,如果(CX)!=0,则跳转。
这两个指令可以一起记忆。所有的条件跳转都只能实现短转移。
- 检测比较结果的条件跳转指令(通常和
cmp连用)
| 指令 | 含义 | 检测的相关标志位 |
|---|---|---|
| je | 等于则转移 | zf=1 |
| jne | 不等于则转移 | zf=0 |
| jb | 低于则转移 | cf=1 |
| jnb | 不低于则转移 | cf=0 |
| ja | 高于则转移 | cf=0且zf=0 |
| jna | 不高于则转移 | cf=1或zf=1 |
函数调用
ret把IP的值出栈,实现近转移;retf把CS和IP的值进栈/出栈,实现远转移。注意CS的值在高位。call不能实现短转移,以下几种转移方法,可以和jmp的方法类比call 标号:令IP进栈,实现近转移(-32768~32767),仍然注意内存的存放问题;call far ptr 标号,令CS和IP先后进栈,实现段间转移;call 16位reg,压栈IP,用寄存器的值修改IP的值;- 转移地址在内存中:
call word ptr 内存单元地址,相当于实现近转移;call dword ptr 内存单元地址,相当于实现段间转移。
环境配置
系统参数
为了防止提供的文件污染环境,选择使用VMware的虚拟机来运行。
系统版本:Windows XP SP2 64bit
虚拟机:VMware Workstation 17 Pro
多说一句,选XP是因为,支持运行DOS和masm,并且虚拟机的速度相对比较快。
所需软件
- DOSBox0.74-2-win32
- masmplus
- DEBUG32
- DEBUG
注:王爽老师的汇编语言教材使用的是DEBUG,而学校提供的是DEBUG 32。二者差不多,指令也差不多,但是DEBUG32不支持MOV AX, [0]这种指令,即指令中不能出现中括号。下载地址
具体步骤
- 关闭防火墙
- 双击安装DOSBox,地址可以用默认的,反正是虚拟机
- 双击安装masmplus,如果发现显示乱码,可能是当前系统不支持中文,自行检索给对应系统安装中文的办法
- 把DEBUG或DEBUG32放到
masmplus的安装目录/Project下。例如,我的masmplus安装在C:/Assembly/masmplus下,则把两个DEBUG放到C:/Assembly/masmplus/Project下。 - 打开DOSBox,输入
mount c: C:/Assembly/masmplus/Project,每次重新打开都要输入。 - 输入
c:,切换到c:盘符,输入debug或debug32进入调试。 - 使用
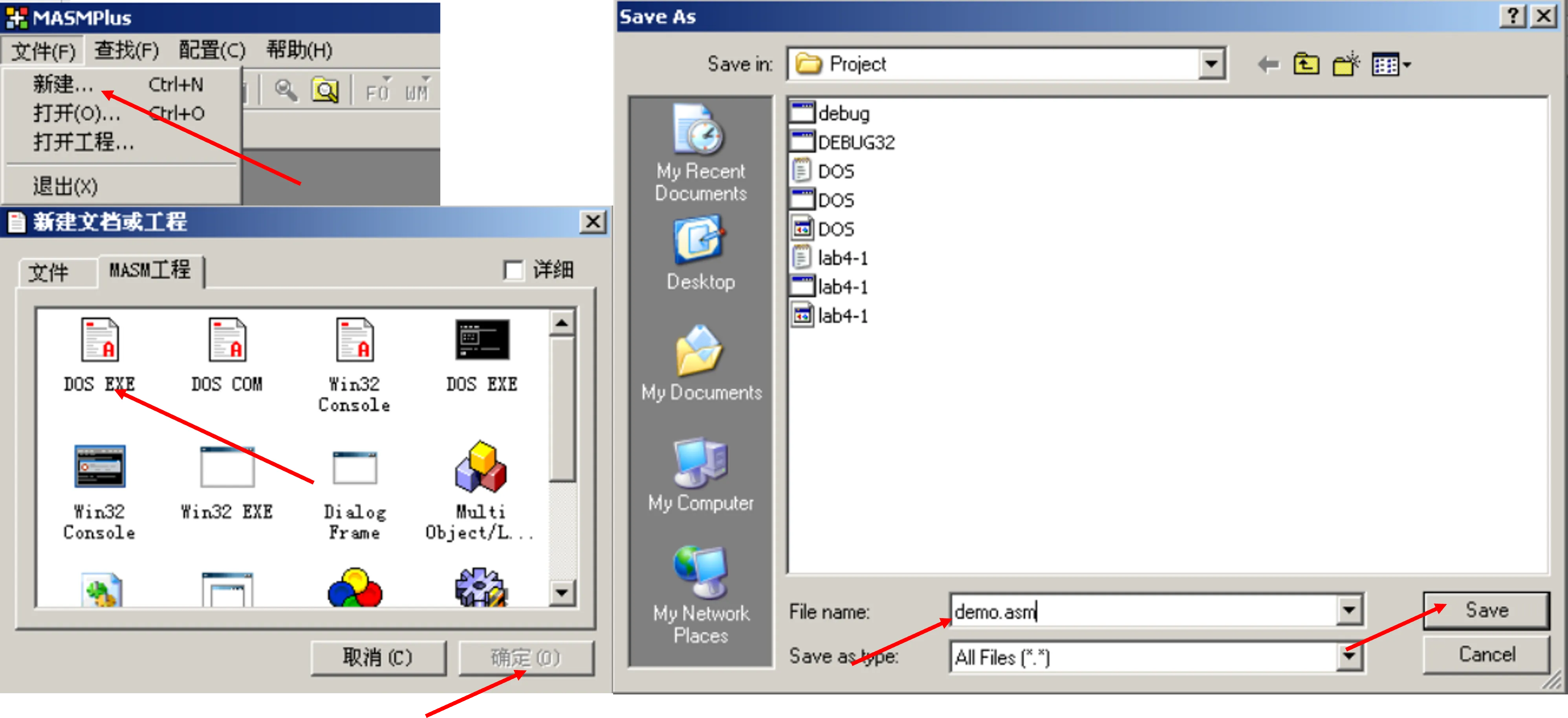
asmsplus编写文件:文件->新建->MASM工程->第一个DOS EXE->确定->修改文件名,注意以.asm结尾->Save。最后会得到一个默认程序。可以完全删掉,因为默认程序的语法和王爽的书上的语法略有不同,后者也可以在DOS和masm的环境跑起来。
- 编写好文件后,点击
编译->编译(ASM)->连接(OBJ),最终得到了一个同文件名,扩展名为.exe的文件。

- 要运行,在DOS下输入
文件名即可 - 要在
Debug下调试,在DOS下输入Debug 文件名即可
Debug的使用
Debug 有几个比较常用的指令:
| 命令 | 功能 | 助记 |
|---|---|---|
| 查看与修改内容 | ||
| r | 查看寄存器的内容 | Register |
| d | 查看一块内存空间的内容 | Dump |
| e | 修改一块内存的内容 | Edit |
| 程序的执行 | ||
| t | 单步执行某个程序 | Trace |
| g | 跳转到某个偏移地址执行指令 | Go |
| p | 执行循环,直到cx为0为止 | Ptrong |
| 汇编相关 | ||
| a | 选定一块内存空间,进行汇编程序的编写 | Assemble |
| u | 将内存的内容反汇编 | Unassemble |
具体的使用方法,这里就不赘述了,请参见王爽的教材。
在编辑器中编写一个.asm程序
示例使用的是masmplus,使用其他编辑器也可以。
程序的基本框架如下:
1 | ; An example program |
其中,datasg、stacksg、codesg分别代表数据段、栈段以及代码段。因为一个段最大只能占64KB,因此把代码分段进行处理可以让看代码的人更容易理解、同时程序在执行过程中更不容易出错。
assume把寄存器和对应的段关联起来,我们不关心它具体的作用,就把它当成汇编源程序编译之前的必要吟唱吧。
start:表明了程序执行的第一条语句,IP会指向它。如果代码段的第一条语句并不是第一条想要执行的语句,就需要加上start:,同时,在end后也要把start写上。这里,start只是一个名字,换成aa也是可以的,只需要确保和end后面的名字对应。
注意,上边提到的datasg等段名仍然只是一个标号。如何让CPU知道各个段的含义呢?
- 对于代码段,
start:标号指向的语句为程序的入口,CS:IP会指向这条语句的首地址,也就让其所在的codesg成为了代码段; - 对于栈段和数据段,通过在代码段中,把段名送入对应的段寄存器中,就实现了寄存器和段的关联。
寻址
寻址的方法列举如下
- 立即数:
MOV AX, 1000H,等价于(AX)=1000H。之前没有说过这个符号,(寄存器名/地址)指的是这个寄存器或地址存储的值。 - 寄存器:
MOV AX, BX,等价于(AX)=(BX)。注意位数到对应,8bit对8bit,16bit对16bit。错误示例:MOV AX, BL。 - 直接寻址:
MOV AX, [1000H]。如果(1000H)=2345H,则该语句使得(AX)=2345H。这里要说明,在Debug中,[0]理解为DS:0,而在masm中,[0]理解为数字0。 - 直接寻址——数据标号法:
MOV AX, VAL。如果(VAL)=2345H,则该语句使得(AX)=2345H。也要注意位数的对应。 - 间接寻址:
MOV AX, [BX]。如果(BX)=2345H,则该语句使得(AX)=2345H。注意,几个通用寄存器中,只有[BX]可以用来间接寻址。还可以间接寻址的有:BP,SI,DI,它们默认的段寄存器不全相同。 - 相对寻址:
MOV AX, VAL[COUNT],(AX)=(DS:(VAL+COUNT))。 - 基址变址寻址:
MOV AX,[BP][DI],(AX)=(SS:(BP+DI))。两层括号,强调存进去的是地址存储的值,而不是地址本身。且必须一个基址+一个变址,不可以两个寄存器类型相同。 - 相对基址变址寻址,是上边两个的结合,可以类比。
MOV AX, VAL[BI][SI]
这几种寻址方法,各有各的应用场景。到底采取哪种寻址方法,和寻址的要求是密切相关的。换句话说,如果需要一个变量,[BX]就足够了,如果要两个变量,可能就需要[BX]和[DI]共同起作用,如果还需要一个常量,那就需要idata。这里不去阐述到底哪种数据类型适合哪种寻址方式,只是点到为止。但需要强调的是,如果要采取基址变址的寻址方式,一定是一个基址寄存器+一个变址寄存器的形式!
伪指令
db、dw、dd
db用来定义字节型数据,Define Bytedw用来定义字型数据,Define Worddd用来定义双字型数据,Define Dword
dup
dup用来进行数据的重复。
如db 3 dup (0)定义了三个字节宽度的内容,每个字节的内容都是0。
offset
offset用来计算标号的偏移地址,相对于谁的偏移地址呢?相对于段地址的!哪个段地址?写在assume伪指令里的。
看一个有些难度的例子:
1 | assume cs:codesg |
这段代码的作用,是把第一条指令复制到s0标号处。
数据标号
之前的程序,使用的是地址标号来表示数据的地址:
1 | ;例子摘自王爽《汇编语言 第三版》P287 |
在上面的例子中,使用标号a、b指明了代码段中一些数据存放的地址。通过offset伪代码可以计算出对应地址,进行数据的操作。
但如果去掉:呢?
1 | ;例子摘自王爽《汇编语言 第三版》P288 |
此时的a、b具有两层含义:
- 表示内存地址
- 表示单元长度
例如,a标号表示了8个数字中第一个数字的字节地址,并且指明了每个数据占一个字节。
通过这样的方法,寻址表达更加简洁。
问题是,计算机怎么知道一个数据编号到底代表哪里?换句话说,有多个段的情况,应该如何处理?
知道偏移量,相对于哪个代码段的偏移量呢?编译器怎么知道?CPU又怎么知道呢?
- 对于编译器问题的解答:编译器通过
assume伪指令把寄存器和代码段关联起来。例如,assume cs:codesg让编译器认为,codesg的段地址存放在CS中。 - 对于CPU问题的解答:CPU通过访问对应段寄存器的值寻找对应的段地址。
举个例子,
1 | ; 自己想的例子 |
当写下mov dl, a的时候,CPU在编译器的帮助下,理解的指令是这样的:
mov dl, ds:a,也是mov dl, ds:[0]
- 编译器做了什么?在编译的时候,看到标号
a。”a在哪里?“,编译器问道。由第二行的伪指令assume,它知道,应该到数据段中寻找,把a标号的段地址理解为数据段的; - CPU做了什么?他通过编译器的翻译,知道了,
a的偏移地址要到DS中寻找,把我们写的源程序理解为mov dl, ds:a; - 我们应该做什么?写好
assume伪指令,把寄存器和数据段对应正确,让编译器理解清楚;给对应的段寄存器通过mov指令正确赋值,使得CPU能够访问到正确的段地址。
直接定址表
如果要把内存当中的0-F输出为字符0-F,有什么好的方法吗?
当然可以注意到,数字0-9和字符0-9,数字A-F和字符A-F之间各自有对应的线性映射。但问题是,这两个映射并不是同一个映射,一个是+30H,另一个是+37H。怎么才好?分类讨论不够方便,如果能建立一个表格就好了。
table db 0123456789ABCDEF
这样,根据数字的偏移量,就可以通过table[bx]来访问对应的字符啦!这就是一个通用的线性映射。
中断
这里,我们只关注内中断。本来中断就不是授课内容,所以这部分是感兴趣才阅读下来的。和外中断相比,还是内中断更重要一些。为什么呢?因为理解了中断,才能明白程序最后的两句:
1 | mov ax, 4c00h |
到底是什么意思啊!
关于中断的总结,从略,总结的目的是为了理解上面两行代码。
中断的过程是:
- CPU收到中断信息
- 将
标志寄存器压栈,设置CS和IP,并且置TF和IF为0 - 根据中断向量表,寻找到相应中断编号的中断处理程序入口地址
- 中断处理程序开始运行
理解这两行的背景知识:
AH存放调用的子程序AL存放参数int意思是调用中断处理程序
所以,这两行的意思是:
- 传递
4c00h给AX - 调用
21h号中断处理程序的4c号子程序 - 根据
al的值,返回值为0